
In dit artikel zullen we de details van het Histogram van georiënteerde gradiënten (HOG) functie descriptor leren. We zullen leren wat er onder de motorkap zit en hoe deze descriptor intern wordt berekend door OpenCV, MATLAB en andere pakketten.
dit bericht maakt deel uit van een serie die ik schrijf over beeldherkenning en objectdetectie.
de volledige lijst van tutorials in deze serie wordt hieronder gegeven:
- beeldherkenning met behulp van traditionele computer Vision technieken : Deel 1
- Histogram van georiënteerde gradiënten: deel 2
- voorbeeldcode voor beeldherkenning: deel 3
- Training a better eye detector: deel 4a
- objectdetectie met behulp van traditionele Computervisietechnieken: deel 4b
- uw eigen OpenCV-objectdetector trainen en testen: deel 5
- beeldherkenning met behulp van Deep Learning : Deel 6
- Inleiding tot neurale netwerken
- inzicht in Feedforward neurale netwerken
- beeldherkenning met behulp van convolutionele neurale netwerken
- objectdetectie met Deep Learning: Deel 7
veel dingen zien er moeilijk en mysterieus uit. Maar als je eenmaal de tijd neemt om ze te deconstrueren, wordt het mysterie vervangen door meesterschap en dat is waar we op uit zijn. Als je een beginner bent en computervisie moeilijk en mysterieus vindt, onthoud dan het volgende
Q: Hoe eet je een olifant ?
A : Eén hap per keer.
- Wat is een Functiedescriptor?
- hoe Histogram van georiënteerde gradiënten berekenen ?
- Stap 1 : Voorbewerking
- Stap 2: Bereken de Gradiëntafbeeldingen
- Stap 3: Bereken Histogram van gradiënten in 8 × 8 cellen
- Stap 4 : 16×16 blok normalisatie
- Stap 5: Bereken de hog feature vector
- Histogram van georiënteerde gradiënten visualiseren
- Abonneren & Downloadcode
Wat is een Functiedescriptor?
een functiedescriptor is een representatie van een afbeelding of een afbeeldingspatch die de afbeelding vereenvoudigt door nuttige informatie uit te pakken en vreemde informatie weg te gooien.
een feature descriptor Converteert een afbeelding met grootte breedte x Hoogte x 3 (kanalen ) naar een feature vector / array van lengte n. in het geval van de HOG feature descriptor, de invoerafbeelding is van grootte 64 x 128 x 3 en de output feature vector is van lengte 3780.
Houd er rekening mee dat HOG descriptor kan worden berekend voor andere formaten, maar in dit bericht houd ik me aan de cijfers in het originele papier zodat u het concept gemakkelijk kunt begrijpen met een concreet voorbeeld.
dit klinkt allemaal goed, maar wat is ” nuttig “en wat is” vreemd”? Om “nuttig” te definiëren, moeten we weten waar het “nuttig” voor is ? Het is duidelijk dat de feature vector is niet nuttig voor het doel van het bekijken van de afbeelding. Maar het is erg handig voor taken zoals beeldherkenning en objectdetectie. De feature Vector geproduceerd door deze algoritmen wanneer ingevoerd in een beeld classificatie algoritmen zoals ondersteuning Vector Machine (SVM) produceren goede resultaten.
maar welke soorten “features” zijn nuttig voor classificatietaken ? Laten we dit punt bespreken met behulp van een voorbeeld. Stel dat we een objectdetector willen bouwen die knoppen van overhemden en jassen detecteert.
een knoop is rond (kan er elliptisch uitzien in een afbeelding ) en heeft meestal een paar gaten voor het naaien. U kunt een randdetector op het beeld van een knop draaien, en gemakkelijk vertellen of het een knop is door simpelweg alleen naar de randafbeelding te kijken. In dit geval is randinformatie “nuttig” en kleurinformatie niet. Daarnaast moeten de functies ook discriminatieve kracht hebben. Bijvoorbeeld, goede functies uit een afbeelding moet in staat zijn om het verschil tussen knoppen en andere cirkelvormige objecten zoals munten en autobanden vertellen.
in de HOG feature descriptor wordt de verdeling ( histogrammen ) van gradiëntenrichtingen (georiënteerde gradiënten ) als Kenmerken Gebruikt. Gradiënten (X en y afgeleiden ) van een afbeelding zijn nuttig omdat de grootte van gradiënten groot is rond randen en hoeken ( gebieden met abrupte intensiteitsveranderingen) en we weten dat randen en hoeken veel meer informatie over objectvorm bevatten dan vlakke gebieden.
hoe Histogram van georiënteerde gradiënten berekenen ?
in deze sectie zullen we ingaan op de details van het berekenen van de HOG feature descriptor. Om elke stap te illustreren, gebruiken we een patch van een afbeelding.
Stap 1 : Voorbewerking
zoals eerder vermeld wordt de HOG feature descriptor gebruikt voor voetgangers detectie berekend op een 64×128 patch van een afbeelding. Natuurlijk kan een afbeelding van elke grootte zijn. Meestal worden patches op meerdere schalen geanalyseerd op veel beeldlocaties. De enige beperking is dat de patches die worden geanalyseerd een vaste beeldverhouding hebben. In ons geval moeten de patches een beeldverhouding van 1: 2 hebben. Ze kunnen bijvoorbeeld 100×200, 128×256 of 1000×2000 zijn, maar niet 101×205.
om dit punt te illustreren heb ik een grote afbeelding van 720×475 getoond. We hebben een patch van grootte 100×200 geselecteerd voor het berekenen van onze HOG feature descriptor. Deze patch wordt uit een afbeelding gesneden en verkleind tot 64×128. Nu zijn we klaar om de HOG descriptor voor deze image patch te berekenen.

het artikel van Dalal en Triggs noemt ook gammacorrectie als een preprocessing stap, maar de prestatiewinst is klein en dus slaan we de stap over.
Stap 2: Bereken de Gradiëntafbeeldingen
om een HOG descriptor te berekenen, moeten we eerst de horizontale en verticale gradiënten berekenen; we willen immers het histogram van gradiënten berekenen. Dit wordt gemakkelijk bereikt door de image te filteren met de volgende kernels.
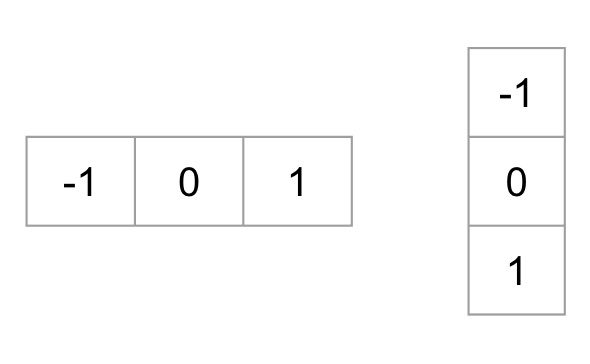
we kunnen ook dezelfde resultaten bereiken, door Sobel operator te gebruiken in OpenCV met kernelgrootte 1.
// C++ gradient calculation.// Read imageMat img = imread("bolt.png");img.convertTo(img, CV_32F, 1/255.0);// Calculate gradients gx, gyMat gx, gy;Sobel(img, gx, CV_32F, 1, 0, 1);Sobel(img, gy, CV_32F, 0, 1, 1);
# Python gradient calculation # Read imageim = cv2.imread('bolt.png')im = np.float32(im) / 255.0# Calculate gradientgx = cv2.Sobel(img, cv2.CV_32F, 1, 0, ksize=1)gy = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=1)
vervolgens kunnen we de grootte en de richting van de gradiënt vinden met behulp van de volgende formule

als u OpenCV gebruikt, kan de berekening worden gedaan met behulp van de functie cartToPolar zoals hieronder weergegeven.
// C++ Calculate gradient magnitude and direction (in degrees)Mat mag, angle;cartToPolar(gx, gy, mag, angle, 1);
dezelfde code in python ziet er zo uit.
# Python Calculate gradient magnitude and direction ( in degrees )mag, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)
onderstaande afbeelding toont de verlopen.
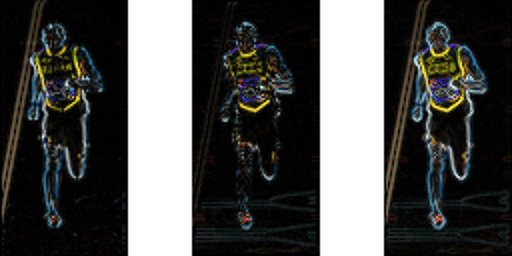
let op, de x-gradiënt vuurt op verticale lijnen en de y-gradiënt vuurt op horizontale lijnen. De omvang van gradiëntbranden waar er ooit een scherpe verandering in intensiteit is. Geen van hen schiet als het gebied glad is. Ik heb bewust het beeld dat de richting van de gradiënt toont weggelaten omdat de richting die als afbeelding wordt getoond niet veel overbrengt.
de gradiëntafbeelding verwijderde veel niet-essentiële informatie (bijvoorbeeld constante gekleurde achtergrond), maar markeerde de contouren. Met andere woorden, je kunt kijken naar de gradiënt afbeelding en nog steeds gemakkelijk zeggen dat er een persoon in de afbeelding.
bij elke pixel heeft het verloop een magnitude en een richting. Voor kleurenafbeeldingen worden de gradiënten van de drie kanalen geëvalueerd (zoals weergegeven in de figuur hierboven ). De magnitude van de gradiënt bij een pixel is het maximum van de magnitude van de gradiënten van de drie kanalen, en de hoek is de hoek die overeenkomt met de maximale gradiënt.
Stap 3: Bereken Histogram van gradiënten in 8 × 8 cellen

in deze stap, wordt het beeld verdeeld in 8×8 cellen en een histogram van gradiënten wordt berekend voor elke 8×8 cellen.
we zullen zo meer te weten komen over de histogrammen, maar voordat we er naartoe gaan, laten we eerst begrijpen waarom we het beeld hebben verdeeld in 8×8 cellen. Een van de belangrijke redenen om een functiedescriptor te gebruiken om een patch van een afbeelding te beschrijven is dat het een compacte representatie biedt. Een 8×8 image patch bevat 8x8x3 = 192 pixel waarden. De gradiënt van deze patch bevat 2 waarden ( magnitude en richting ) per pixel wat neerkomt op 8x8x2 = 128 getallen.
aan het einde van deze sectie zullen we zien hoe deze 128 getallen worden weergegeven met behulp van een 9-bin histogram dat kan worden opgeslagen als een array van 9 getallen. Niet alleen is de representatie compacter, het berekenen van een histogram over een patch maakt deze representatie robuuster voor ruis. Individuele graidenten kunnen ruis hebben, maar een histogram over 8×8 patch maakt de voorstelling veel minder gevoelig voor ruis.
maar waarom 8×8 patch ? Waarom niet 32×32 ? Het is een ontwerp keuze gebaseerd op de schaal van de functies die we zoeken. HOG werd in eerste instantie gebruikt voor voetgangersdetectie. 8×8 cellen in een foto van een voetganger met een schaal van 64×128 zijn groot genoeg om interessante kenmerken vast te leggen ( bijvoorbeeld het gezicht, de bovenkant van het hoofd enz. ).
het histogram is in wezen een vector (of een array ) van 9 bins (getallen ) die overeenkomen met hoeken 0, 20, 40, 60 … 160.
laten we een 8×8 vlak in de afbeelding bekijken en zien hoe de verlopen eruit zien.
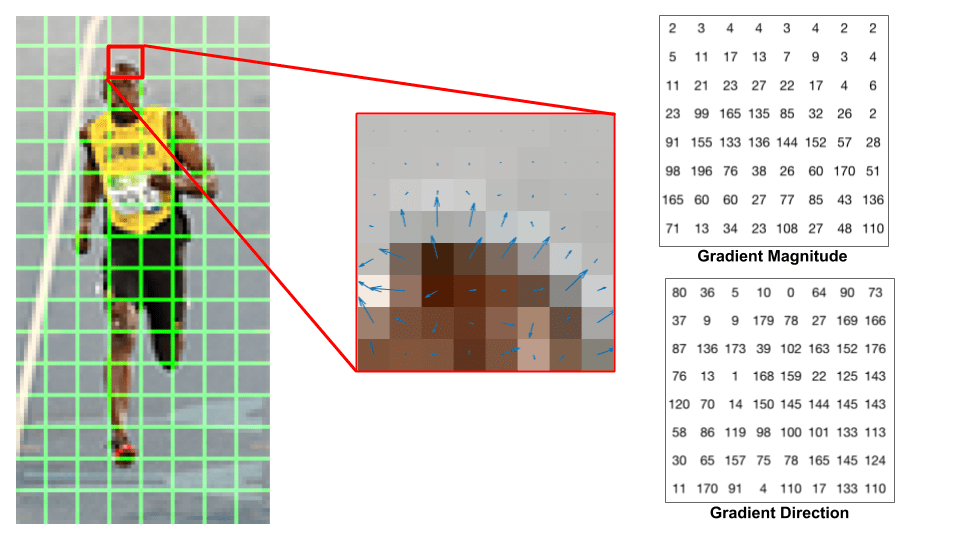
als je een beginner bent in computer vision, is het beeld in het centrum zeer informatief. Het toont het vlak van de afbeelding bedekt met pijlen die het verloop tonen — de pijl toont de richting van het verloop en de lengte toont de magnitude. Merk op hoe de richting van de pijlen wijst naar de richting van verandering in intensiteit en de magnitude laat zien hoe groot het verschil is.
rechts zien we de ruwe getallen die de gradiënten in de 8×8 cellen weergeven met één klein verschil — de hoeken liggen tussen 0 en 180 graden in plaats van 0 tot 360 graden. Deze worden” unsigned ” gradiënten genoemd omdat een gradiënt en het negatief zijn vertegenwoordigd door dezelfde getallen. Met andere woorden, een gradiëntpijl en de 180 graden tegenovergestelde ervan worden als hetzelfde beschouwd. Maar, waarom niet gebruik maken van de 0-360 graden ?
empirisch is aangetoond dat niet-ondertekende gradiënten beter werken dan ondertekende gradiënten voor voetgangers detectie. Met sommige implementaties van HOG kunt u aangeven of u ondertekende verlopen wilt gebruiken.
de volgende stap is het maken van een histogram van gradiënten in deze 8×8 cellen. Het histogram bevat 9 bakken die overeenkomen met hoeken 0, 20, 40 … 160. De volgende figuur illustreert het proces. We kijken naar magnitude en richting van de gradiënt van dezelfde 8×8 patch als in de vorige figuur.
een bin wordt geselecteerd op basis van de richting, en de stem ( de waarde die in de bin gaat ) wordt geselecteerd op basis van de magnitude. Laten we ons eerst concentreren op de pixel omcirkeld in blauw. Het heeft een hoek ( richting ) van 80 graden en een magnitude van 2. Dus het voegt 2 toe aan de 5e bak. De gradiënt op de pixel omcirkeld met rood heeft een hoek van 10 graden en magnitude van 4. Aangezien 10 graden halverwege tussen 0 en 20 ligt, splitst de stem van de pixel zich gelijkmatig in de twee bakken.
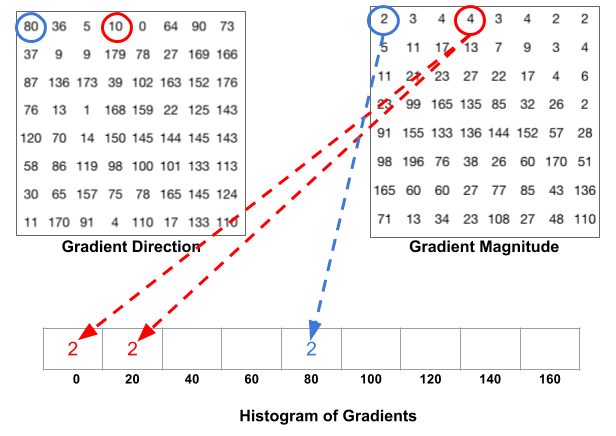
er is nog een detail om je bewust van te zijn. Als de hoek groter is dan 160 graden, is het tussen 160 en 180, en we weten dat de hoek rond het maken van 0 en 180 equivalent is. Dus in het voorbeeld hieronder draagt de pixel met hoek 165 graden proportioneel bij aan de 0 graden bin en de 160 graden bin.
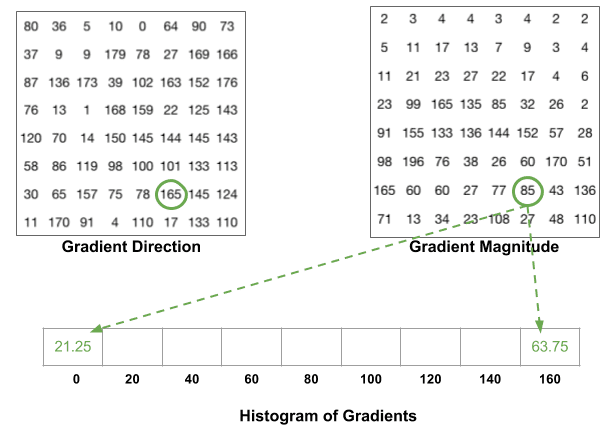
de bijdragen van alle pixels in de 8×8 cellen worden opgeteld om het 9-bin histogram te maken. Voor de patch hierboven ziet het er zo uit
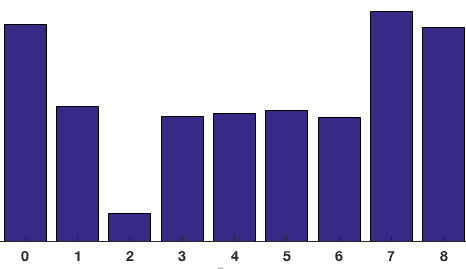
in onze voorstelling is de y-as 0 graden. Je kunt zien dat het histogram veel gewicht heeft in de buurt van 0 en 180 graden, wat gewoon een andere manier is om te zeggen dat in de patch gradiënten naar boven of naar beneden wijzen.
Stap 4 : 16×16 blok normalisatie
in de vorige stap hebben we een histogram gemaakt op basis van de gradiënt van de afbeelding. Gradiënten van een afbeelding zijn gevoelig voor algemene verlichting. Als u de afbeelding donkerder maakt door alle pixelwaarden door 2 te delen, zal de gradiëntgrootte met de helft veranderen, en daarom zullen de histogramwaarden met de helft veranderen.
idealiter willen we dat onze descriptor onafhankelijk is van lichtvariaties. Met andere woorden, we willen het histogram “normaliseren”, zodat ze niet worden beïnvloed door lichtvariaties.
voordat ik uitleg hoe het histogram genormaliseerd is, laten we eens kijken hoe een vector van lengte 3 genormaliseerd is.
laten we zeggen dat we een RGB-kleurvector hebben . De lengte van deze vector is $\sqrt{128^2 + 64^2 + 32^2} = 146.64$. Dit wordt ook wel de L2 norm van de vector genoemd. Het delen van elk element van deze vector door 146,64 geeft ons een genormaliseerde vector .
overweeg nu een andere vector waarin de elementen tweemaal de waarde van de eerste vector 2 x = zijn . U kunt het zelf uit te werken om te zien dat het normaliseren zal resulteren in , dat is hetzelfde als de genormaliseerde versie van de oorspronkelijke RGB vector. U kunt zien dat het normaliseren van een vector de schaal verwijdert.
nu we weten hoe we een vector moeten normaliseren, zou je geneigd kunnen zijn om te denken dat je tijdens het berekenen van HOG gewoon het 9×1 histogram kunt normaliseren op dezelfde manier als we de 3×1 vector hierboven hebben genormaliseerd. Het is geen slecht idee, maar een beter idee is om te normaliseren over een groter formaat blok van 16×16.
een 16×16 blok heeft 4 histogrammen die kunnen worden samengevoegd tot een 36 x 1 element vector en het kan worden genormaliseerd net zoals een 3×1 vector is genormaliseerd. Het venster wordt dan verplaatst met 8 pixels (zie animatie) en een genormaliseerde 36×1 vector wordt berekend over dit venster en het proces wordt herhaald.
Stap 5: Bereken de hog feature vector
om de uiteindelijke feature vector voor de gehele afbeelding te berekenen, worden de 36×1 vectoren samengevoegd tot één giant vector. Wat is de grootte van deze vector ? Laten we
- berekenen hoeveel posities van de 16 × 16 blokken hebben we ? Er zijn 7 horizontale en 15 verticale posities, dus in totaal 7 x 15 = 105 posities.
- elk blok van 16×16 wordt weergegeven door een vector van 36×1. Dus als we ze allemaal samenvoegen tot één gaint vector krijgen we een 36×105 = 3780 dimensionale vector.
Histogram van georiënteerde gradiënten visualiseren

de HOG descriptor van een beeld patch wordt meestal gevisualiseerd door het plotten van de 9×1 genormaliseerde histogrammen in de 8×8 cellen. Zie afbeelding aan de zijkant. U zult merken dat de dominante richting van het histogram de vorm van de persoon vangt, vooral rond de romp en de benen.
helaas is er geen eenvoudige manier om de HOG descriptor in OpenCV te visualiseren.