Katso myös
FASTQ-tiedostot
Keskimääräinen Q on huono idea!
odotetut virheet
Laatusuodatus
pohjan laatuarvo, joka tunnetaan myös nimellä Phred – tai Q-pisteet, on kokonaisluku, joka kuvaa virheen estimoitua todennäköisyyttä eli sitä, että pohja on virheellinen. Jos P on virhetodennäköisyys, niin:
P = 10-Q/10
Q = -10 log10(P)
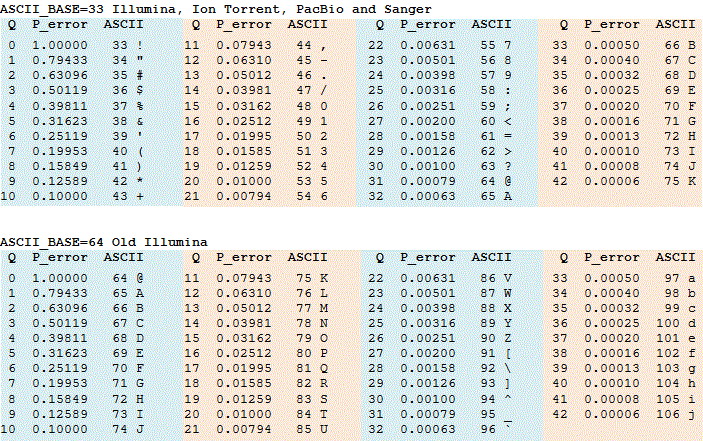
Q-pisteet esitetään usein ASCII-merkkeinä. Sääntö ASCII-merkin muuntamiseksi kokonaisluvuksi vaihtelee, katso tarkemmat tiedot fastq-vaihtoehdoista. Taulukoita muunnetaan kokonaisluku Q-pisteiden, ASCII-merkkien ja virhetodennäköisyyksien välillä on esitetty alla olevassa taulukossa ASCII_BASE 33, joka on nykyisin lähes yleisesti käytössä, ja ascii_base 64, jota käytetään joissakin vanhemmissa Illumina-tiedoissa.
millainen virhe?
lukemissa 454 ja Illumina on merkittävä ero Q-pisteiden välillä. 454 jättää korvausvirheiden mahdollisuuden huomiotta ja Illumina jättää indelit huomioimatta. 454: llä Q-pistemäärä on arvioitu todennäköisyys sille, että homopolymeerin pituus on väärä, ja Illuminalla Q-pistemäärä on todennäköisyys sille, että kantakutsu on virheellinen. Illuminan tapauksessa tämä on järkevää, koska indel-virheet ovat hyvin harvinaisia. Mutta 454: llä korvausvirheet ovat melko yleisiä, ja niitä esiintyy yhtä usein kuin homopolymeerivirheitä. Tämä tarkoittaa, että 454 Q-pisteet eivät ole yhtä informatiivisia kuin Illumina Q-pisteet, mutta ovat silti käyttökelpoisia käytännössä. Katso lisätietoja laatusuodatuksesta.
Pienet Q-pisteet
huomaa, että Q-pistemäärä 3 tarkoittaa P=0.5, mikä tarkoittaa, että on olemassa 50% mahdollisuus pohja on väärä, ja alemmat arvot edustavat vieläkin suurempi todennäköisyys virhe. Q=0 tarkoittaa P = 1, eli että kantakutsu on varmasti väärä, joten tätä käytetään harvoin, vaikka se saattaa sopia määrittelemättömälle kantaluvulle (usein edustettuna ”N”). En ole koskaan nähnyt FASTQ-tiedostoa, jossa Q=0, mutta koska formaattia ei ole standardoitu, en voi olla varma. Alin yleensä käytännössä havaittu arvo on Q=2 (P=0,63), eli kantakutsu on todennäköisemmin väärä kuin oikea.
tiedostomuodon tunnistaminen
fastx_info-ja fastq_chars-komentoja voidaan käyttää formaatin määrittämiseen. Tärkein parametri on ASCII_BASE, joka tietääkseni on aina 33 tai 64. Tyypillisellä alueella Q2-Q40, tämä antaa alueen ASCII arvot 35-73 ascii_base=33 ja 66-104 ascii_base=64. Nämä alueet limittyvät ASCII 66: sta 73: een. Myös arvot >Q40 voidaan tuottaa jollakin koneohjelmistolla ja joillakin jälkikäsittelyohjelmistoilla, kuten paritetuilla lukukokoonpanoilla. Jos siis näemme ASCII-arvot >73, se ei välttämättä tarkoita, että meillä olisi ascii_base=64, nämä voisivat olla korkealaatuisia pisteitä ascii_base=33. Ainoa varma tapa erottaa varmasti on, jos näemme ASCII-arvot < 64, jolloin tiedämme ASCII_BASE=33. Nopea tapa tarkistaa silmämääräisesti on etsiä # ja$, mikä tarkoittaa ASCII_BASE=33 tai pienaakkosia, mikä todennäköisesti tarkoittaa ASCII_BASE=64.