Se også
FASTQ files
Gjennomsnittlig Q er en dårlig ide!
Forventede feil
kvalitetsfiltrering
kvalitetspoengene til en base, også Kjent Som En Phred-eller Q-score, er en heltallsverdi som representerer den estimerte sannsynligheten for en feil, dvs.at basen er feil. Hvis P er feilsannsynligheten, så:
P = 10-Q/10
Q = -10 log10(P)
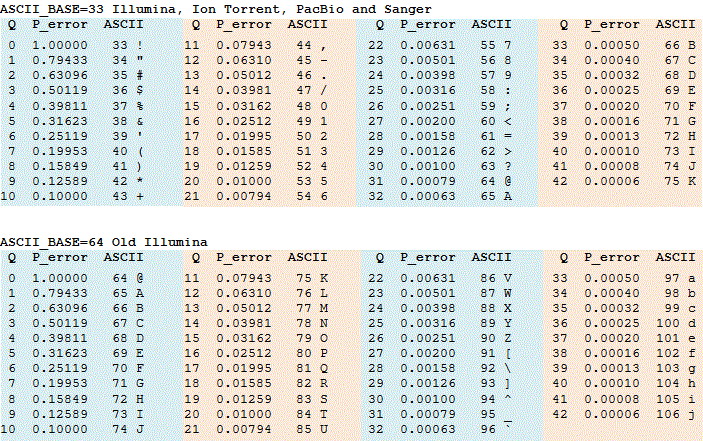
q score er ofte representert SOM ASCII-tegn. Regelen for å konvertere ET ASCII-tegn til et heltall varierer, se FASTQ-alternativer for detaljer. Tabeller konvertere mellom heltall q score, ASCII-tegn og feil sannsynligheter er vist i tabellen under ASCII_BASE 33, som nå er nesten universelt brukt, OG ASCII_BASE 64 som brukes i noen eldre Illumina data.
Hva slags feil?
Det er en viktig forskjell Mellom q score i leser fra 454 Og Illumina. I praksis ignorerer 454 muligheten for substitusjonsfeil og Illumina ignorerer indels. Med 454 Er q-poengsummen den estimerte sannsynligheten for at lengden på homopolymeren er feil, og Med Illumina Er Q-poengsummen sannsynligheten for at basekallet er feil. I Tilfelle Av Illumina er dette rimelig fordi indel-feil er svært sjeldne. Men med 454 er substitusjonsfeil ganske vanlige, som forekommer med sammenlignbar frekvens til homopolymer feil. Dette betyr at 454 Q-poeng ikke er like informative Som Illumina Q-poeng, men er fortsatt nyttige i praksis. Se kvalitetsfiltrering for videre diskusjon.
Små q score
Merk at En q score på 3 betyr P=0.5, noe som betyr at det er 50% sjanse for at basen er feil, og lavere verdier representerer enda høyere sannsynligheter for feil. Q = 0 betyr P = 1, dvs. at basekallet er sikkert feil, så dette brukes sjelden, men kan være hensiktsmessig for en ubestemt base(ofte representert Som ‘N’). Jeg har aldri sett EN FASTQ-fil Med Q = 0, men siden formatet ikke er standardisert, kan jeg ikke være sikker. Den laveste verdien som vanligvis finnes I praksis Er Q=2 (P=0,63), noe som betyr at basekallet er mer sannsynlig å være feil enn riktig.
Gjenkjenne formatet
kommandoene fastx_info og fastq_chars kan brukes til å bestemme formatet. DEN viktigste parameteren ER ASCII_BASE, som så vidt jeg vet er alltid 33 eller 64. Med et typisk område Fra Q2 Til Q40, gir DETTE EN rekke ASCII-verdier fra 35 til 73 med ASCII_BASE=33 og fra 66 til 104 med ASCII_BASE=64. Disse områdene overlapper FRA ASCII 66 til 73. Også verdier > Q40 kan produseres av noen maskin programvare og av noen etterbehandling programvare som sammenkoblede lese montører. Så hvis VI ser ASCII-verdier > 73 som ikke nødvendigvis betyr at VI har ASCII_BASE=64, kan disse være høy kvalitet score MED ASCII_BASE=33. Den eneste sikre måten å skille sikkert på er om vi ser ASCII-verdier < 64, i så fall vet VI ASCII_BASE=33. En rask måte å sjekke visuelt på er å se etter # og$, som betyr ASCII_BASE=33 eller små bokstaver som sannsynligvis innebærer ASCII_BASE=64.