Se også
hurtigk filer
gennemsnitlig K er en dårlig ide!
forventede fejl
kvalitetsfiltrering
kvalitetsresultatet for en base, også kendt som en Phred-eller K-score, er en heltalsværdi, der repræsenterer den estimerede Sandsynlighed for en fejl, dvs.at basen er forkert. Hvis P er fejlsandsynligheden, så:
P = 10-K/10
K = -10 log10(P)
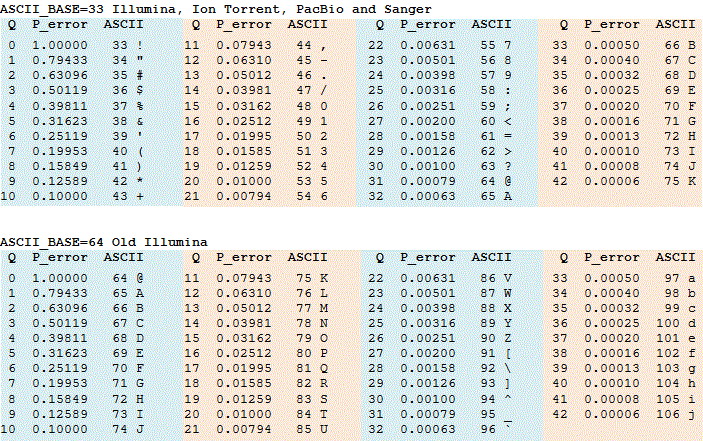
K-scoringer er ofte repræsenteret som ASCII-tegn. Reglen for konvertering af et ASCII-tegn til et heltal varierer. Tabeller, der konverterer mellem heltalsresultater, ASCII-tegn og fejlsandsynligheder, vises i tabellen nedenfor ASCII_BASE 33, som nu næsten bruges universelt, og ASCII_BASE 64, som bruges i nogle ældre Illumina-data.
hvilken slags fejl?
der er en vigtig forskel mellem K-score I læser fra 454 og Illumina. I virkeligheden ignorerer 454 muligheden for substitutionsfejl, og Illumina ignorerer indels. Med 454 er K-score den estimerede Sandsynlighed for, at homopolymerens længde er forkert, og med Illumina er K-score sandsynligheden for, at basisopkaldet er forkert. I tilfælde af Illumina er dette rimeligt, fordi indel-fejl er meget sjældne. Men med 454 er substitutionsfejl ret almindelige, der forekommer med sammenlignelig frekvens til homopolymerfejl. Dette betyder, at 454 Point ikke er så informative som Illumina point, men stadig er nyttige i praksis. Se kvalitetsfiltrering for yderligere diskussion.
små K score
Bemærk at en K score på 3 betyder P=0.5, hvilket betyder, at der er en 50% chance for, at basen er forkert, og lavere værdier repræsenterer endnu højere sandsynligheder for fejl. 0 betyder P = 1, dvs.at basisopkaldet bestemt er forkert, så dette bruges sjældent, men kan være passende for en ubestemt base (ofte repræsenteret som ‘N’). 0, men da formatet ikke er standardiseret, kan jeg ikke være sikker. Den laveste værdi, der normalt findes i praksis, er K=2 (P=0,63), hvilket betyder, at basisopkaldet er mere sandsynligt forkert end korrekt.
genkendelse af formatet
kommandoerne fasth_info og fasth_chars kan bruges til at bestemme formatet. Den vigtigste parameter er ASCII_BASE, som så vidt jeg ved altid er 33 eller 64. Med et typisk interval fra 2. kvartal til 40.kvartal giver dette en række ASCII-værdier fra 35 Til 73 med ASCII_BASE=33 og fra 66 til 104 med ASCII_BASE=64. Disse intervaller overlapper fra ASCII 66 Til 73. Værdier > 40. kvartal kan også produceres af nogle maskinprogrammer og af nogle efterbehandlingsprogrammer, såsom parrede læsesamlere. Så hvis vi ser ASCII-værdier > 73, betyder det ikke nødvendigvis, at vi har ASCII_BASE=64, disse kan være høj kvalitet score med ASCII_BASE=33. Den eneste sikre måde at skelne sikkert på er, hvis vi ser ASCII-værdier < 64, i hvilket tilfælde vi kender ASCII_BASE=33. En hurtig måde at kontrollere visuelt på er at kigge efter # og $, hvilket betyder ASCII_BASE=33 eller små bogstaver, hvilket sandsynligvis indebærer ASCII_BASE=64.