Viz také
FASTQ soubory
Průměrná Q je špatný nápad!
očekávané chyby
filtrování kvality
skóre kvality základny, známé také jako skóre Phred nebo Q, je celočíselná hodnota představující odhadovanou pravděpodobnost chyby, tj. že základna je nesprávná. Pokud P je pravděpodobnost chyby, pak:
P = 10-Q / 10
Q = -10 log10 (P)
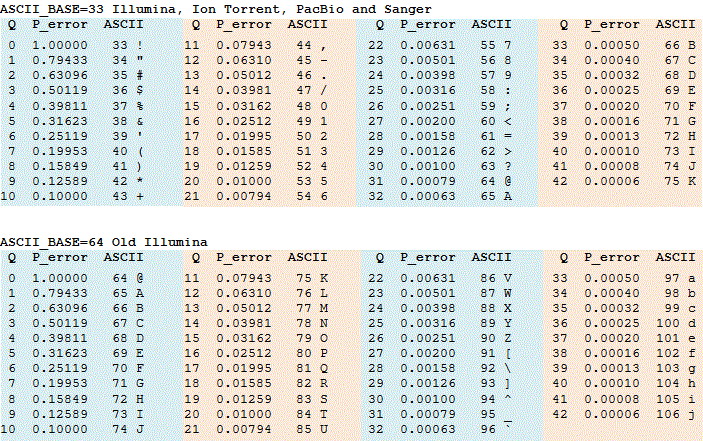
Q skóre jsou často reprezentovány jako znaky ASCII. Pravidlo pro převod znaku ASCII na celé číslo se liší, podrobnosti viz možnosti FASTQ. Tabulky převod mezi integer Q skóre, ASCII znaky a chyba pravděpodobnosti jsou uvedeny v tabulce níže ASCII_BASE 33, který je nyní téměř všeobecně používán, a ASCII_BASE 64, který je použit v některých starších Illumina data.
jaký druh chyby?
existuje důležitý rozdíl mezi Q skóre ve čtení od 454 a Illumina. Ve skutečnosti 454 ignoruje možnost substitučních chyb a Illumina ignoruje indely. U 454 je Q skóre odhadovaná pravděpodobnost, že délka homopolymeru je nesprávná, a u Illuminy Q skóre je pravděpodobnost, že základní volání je nesprávné. V případě Illuminy je to rozumné, protože chyby indel jsou velmi vzácné. U 454 jsou však substituční chyby zcela běžné a vyskytují se se srovnatelnou frekvencí s homopolymerními chybami. To znamená, že 454 Q skóre nejsou tak informativní jako Illumina Q skóre, ale jsou stále užitečné v praxi. Viz filtrování kvality pro další diskusi.
malé Q skóre
Všimněte si, že q skóre 3 znamená P=0.5, což znamená, že existuje 50% šance, že základna je špatná, a nižší hodnoty představují ještě vyšší pravděpodobnost chyby. Q=0 znamená, že P=1, tj. že základní výzva je určitě špatně, takže to je zřídka používán, i když by mohlo být vhodné pro neurčité báze (často reprezentován jako „N“). Nikdy jsem neviděl soubor FASTQ s Q=0, ale protože formát není standardizován, nemohu si být jistý. Nejnižší hodnota, která se obvykle nachází v praxi, je Q=2 (P=0,63), což znamená, že základní volání je pravděpodobnější než správné.
rozpoznání formátu
příkazy fastx_info a fastq_chars lze použít k určení formátu. Nejdůležitějším parametrem je ASCII_BASE, který, pokud vím, je vždy 33 nebo 64. S typickým rozsahu od Q2 do Q40, to dává řadu ASCII hodnoty od 35 do 73 s ASCII_BASE=33 a od 66 do 104 s ASCII_BASE=64. Tyto rozsahy se překrývají od ASCII 66 do 73. Také hodnoty > Q40 mohou být produkovány některým strojním softwarem a některým softwarem pro následné zpracování, jako jsou spárované read assemblery. Pokud tedy vidíme hodnoty ASCII >73, nemusí to nutně znamenat, že máme ASCII_BASE=64, mohou to být vysoce kvalitní skóre s ASCII_BASE=33. Jediný jistý způsob, jak s jistotou rozlišit, je, když vidíme hodnoty ASCII < 64, v takovém případě známe ASCII_BASE=33. Rychlý způsob, jak vizuálně zkontrolovat, je hledat # a$, což znamená ASCII_BASE=33 nebo malá písmena, což pravděpodobně znamená ASCII_BASE=64.