talán a legegyszerűbb iteratív módszer az Ax = b megoldására Jacobi módszere. Ne feledje, hogy ennek a módszernek az egyszerűsége mind jó, mind rossz: jó, mert viszonylag könnyen érthető, és így az iteratív módszerek jó első íze; rossz, mert általában nem használják a gyakorlatban (bár potenciális hasznosságát a párhuzamos számítástechnika). Ennek ellenére jó kiindulópont a hasznosabb, de bonyolultabb iteratív módszerek megismeréséhez.
adott aktuális közelítés
x(k) = (x1(k), x2(k), x3(k), …, xn(k))
X esetében Jacobi módszerének stratégiája az, hogy az első egyenletet és az X2(k), x3(k), …, xn(k) aktuális értékeit használja egy új X1(k+1) érték megtalálásához, és hasonlóan a X1(k + 1) egy új Xi (k) érték az i-edik egyenlet és a többi változó régi értékeinek felhasználásával. Vagyis adott aktuális értékek x(k) = (x1(k), x2(k), …, xn(k)), Keressen új értékeket a
X(k+1) = (x1(k+1), x2(k+1), …, xn (k+1))
a
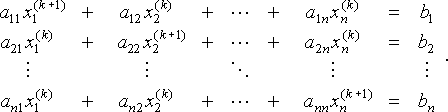
ezt a rendszert úgy is lehet írni, mint

hogy világos legyek, az I Index azt jelenti, hogy xi(k) a
x(k) = (x1(k), x2(k),…, xi(k),…, xn(k)),
vektor i-edik eleme, a K felső index pedig az adott iterációnak felel meg (nem xi k-edik hatványának ).
ha D-T, L-T és U-t írunk az átló, a szigorú alsó háromszög és a szigorú felső háromszög, illetve az a részeire,
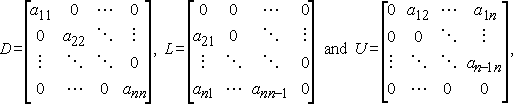
ezután Jacobi módszere mátrix-vektor jelöléssel írható
példa 1
alkalmazzuk Jacobi módszerét a rendszerre
 .
.minden lépésben, figyelembe véve az aktuális értékeket x1(k), x2(k), x3(k), megoldjuk x1(k+1), x2(k+1) és x3(k+1)
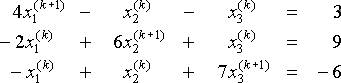 .
.tehát, ha a kezdeti találgatásunk x(0) = (x1(0), x2(0), x3(0)) a nulla vektor 0 = (0,0,0) — egy általános kezdeti találgatás, hacsak nincs olyan további információnk, amely arra késztet minket, hogy válasszunk másikat — akkor megtaláljuk x(1) = (x1 (1), x2(1), x3(1) ) megoldásával
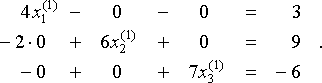
tehát x (1) = (x1 (1), x2 (1), x3(1)) = (3/4, 9/6, -6/7) ≈ (0.750, 1.500, -0.857). Megismételjük ezt a folyamatot, hogy megtaláljuk az egyre jobb közelítések sorozatát x(0), x(1), x(2),…. Az eredményeket az alábbi táblázatban mutatjuk be, az összes értéket 3 tizedesjegyre kerekítve.
minket az e hiba érdekel minden iterációnál a valódi x megoldás és az X(k) közelítés között: e(k) = x − x(k) . Nyilvánvaló, hogy általában nem ismerjük az igazi megoldást x. az iteratív módszer viselkedésének jobb megértése érdekében azonban felvilágosító a módszer használata egy olyan rendszer megoldására Ax = b amelyre ismerjük az igazi megoldást, és elemezzük, hogy a közelítések milyen gyorsan konvergálnak az igazi megoldáshoz. Ebben a példában a valódi megoldás x = (1, 2, -1).
a ||x|| vektor normája megmondja, hogy mekkora a vektor egésze (szemben a vektor egyes elemeinek nagyságával). A lineáris algebrában leggyakrabban használt vektor norma az l2 norma:
például, ha x = (1, 2, -1), akkor
ebben a modulban mindig az l2 normát fogjuk használni (beleértve a mátrix normákat is a következő oktatóanyagokban), így a / / / / mindig azt jelenti|| ||2.
céljainkhoz megfigyeljük, hogy ||x|| pontosan akkor lesz kicsi, ha az x1, x2,…, xn elemek mindegyike x = (x1, x2,…, xn ) kicsi. Az alábbi táblázatban a hiba normája fokozatosan kisebb lesz, mivel a hiba mind a három elemben x1, x2, x3 kisebb lesz, vagy más szavakkal, mivel a közelítések fokozatosan javulnak.
| k | x (k) | x (k)-x (k-1) | e(k) = x − x(k) | ||e (k))|| | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.000 | -0.000 | -0.000 | − | − | − | -0.000 | -0.000 | -1.000 | 2.449 |
| 1 | 0.750 | 1.500 | -0.857 | -0.000 | -0.000 | -0.857 | 0.250 | 0.500 | -0.143 | 0.557 |
| 2 | 0.911 | 1.893 | -0.964 | 0.161 | 0.393 | -0.107 | 0.089 | 0.107 | -0.036 | 0.144 |
| 3 | 0.982 | 1.964 | -0.997 | 0.071 | 0.071 | -0.033 | 0.018 | 0.036 | -0.003 | 0.040 |
| 4 | 0.992 | 1.994 | -0.997 | 0.010 | 0.029 | 0.000 | 0.008 | 0.006 | -0.003 | 0.011 |
| 5 | 0.999 | 1.997 | -1.000 | 0.007 | 0.003 | -0.003 | 0.001 | 0.003 | 0.000 | 0.003 |
| 6 | 0.999 | 2.000 | -1.000 | 0.000 | 0.003 | 0.001 | 0.000 | 0.001 | 0.000 | 0.001 |
| 7 | 1.000 | 2.000 | -1.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 8 | 1.000 | 2.000 | -1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |