kanske är den enklaste iterativa metoden för att lösa Ax = b Jacobis metod. Observera att enkelheten i denna metod är både bra och dålig: bra, eftersom den är relativt lätt att förstå och därmed är en bra första smak av iterativa metoder; dåligt, eftersom det vanligtvis inte används i praktiken (även om dess potentiella användbarhet har omprövats med tillkomsten av parallell databehandling). Ändå är det en bra utgångspunkt för att lära sig mer användbara, men mer komplicerade, iterativa metoder.
med tanke på en aktuell approximation
x(k) = (x1(k), x2(k), x3(k), …, xn(k))
för x är strategin för Jacobis metod att använda den första ekvationen och de aktuella värdena för x2(k), x3(k),…, xn(k) för att hitta ett nytt värde x1(k+1) och på samma sätt ett nytt värde Xi(k) med den i: e ekvationen och de gamla värdena för de andra variablerna. Det vill säga, med tanke på nuvarande värden x (k) = (x1( k), x2 (k),…, xn (k)), hitta nya värden genom att lösa för
x (k + 1) = (x1 (k + 1), x2 (k + 1),…, xn (k+1))
i
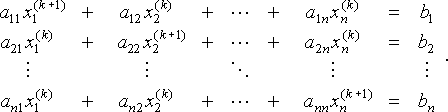
detta system kan också skrivas som

för att vara tydlig betyder prenumerationen i att xi (k) är det i: e elementet i vektorn
x(k) = (x1(k), x2(k),…, xi(k),…, xn(k)),
och superscript k motsvarar den specifika iterationen (inte KTH-kraften i xi).
om vi skriver D, L och U för diagonalen, strikt nedre triangulära och strikta övre triangulära respektive delar av a,
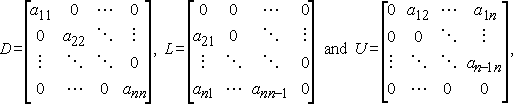
då kan Jacobis metod skrivas i matrisvektornotation som
exempel 1
låt oss tillämpa Jacobis metod på systemet
 .
.vid varje steg, med tanke på de aktuella värdena x1(k), x2(k), X3(k), löser vi för x1 (k + 1), x2(k+1) och x3 (k+1) i
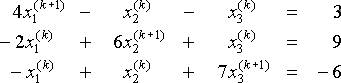 .
.så om vår första gissning x(0) = (x1( 0), x2 (0), x3 (0)) är nollvektorn 0 = (0,0,0) – en vanlig initial gissning om vi inte har ytterligare information som får oss att välja någon annan-då hittar vi x (1) = (x1 (1), x2 (1), x3 (1)) genom att lösa
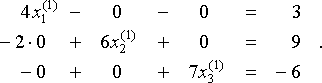
så x (1) = (x1 (1), x2 (1), x3(1)) = (3/4, 9/6, -6/7) ≈ (0.750, 1.500, -0.857). Vi upprepar denna process för att hitta en sekvens av allt bättre approximationer x(0), x(1), x(2), … . Vi visar resultaten i tabellen nedan, med alla värden avrundade till 3 decimaler.
vi är intresserade av felet e vid varje iteration mellan den sanna lösningen x och approximationen x(k): e(k) = x − x(k) . Självklart vet vi vanligtvis inte den sanna lösningen x. Men för att bättre förstå beteendet hos en iterativ metod är det upplysande att använda metoden för att lösa ett system Ax = b för vilket vi känner till den sanna lösningen och analyserar hur snabbt approximationerna konvergerar till den sanna lösningen. I det här exemplet är den sanna lösningen x = (1, 2, -1).
normen för en vektor ||x|| berättar hur stor vektorn är som helhet (i motsats till hur stor varje element i vektorn är). Den vektornorm som oftast används i linjär algebra är L2-normen:
till exempel, om x = (1, 2, -1), då
i den här modulen kommer vi alltid att använda L2-normen (inklusive för matrisnormer i efterföljande handledning), så att / / / / alltid betyder|| ||2.
för våra ändamål observerar vi att ||x|| kommer att vara liten exakt när var och en av elementen x1, x2,…, xn i x = (x1, x2,…, xn ) är liten. I följande tabell blir felnormen gradvis mindre när felet i vart och ett av de tre elementen x1, x2, x3 blir mindre, eller med andra ord, när approximationerna blir gradvis bättre.
| k | x (k) | x (k − – x (k-1) | e (k) = x-x (k) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.000 | -0.000 | -0.000 | − | − | − | -0.000 | -0.000 | -1.000 | 2.449 |
| 1 | 0.750 | 1.500 | -0.857 | -0.000 | -0.000 | -0.857 | 0.250 | 0.500 | -0.143 | 0.557 |
| 2 | 0.911 | 1.893 | -0.964 | 0.161 | 0.393 | -0.107 | 0.089 | 0.107 | -0.036 | 0.144 |
| 3 | 0.982 | 1.964 | -0.997 | 0.071 | 0.071 | -0.033 | 0.018 | 0.036 | -0.003 | 0.040 |
| 4 | 0.992 | 1.994 | -0.997 | 0.010 | 0.029 | 0.000 | 0.008 | 0.006 | -0.003 | 0.011 |
| 5 | 0.999 | 1.997 | -1.000 | 0.007 | 0.003 | -0.003 | 0.001 | 0.003 | 0.000 | 0.003 |
| 6 | 0.999 | 2.000 | -1.000 | 0.000 | 0.003 | 0.001 | 0.000 | 0.001 | 0.000 | 0.001 |
| 7 | 1.000 | 2.000 | -1.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 8 | 1.000 | 2.000 | -1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |