Kanskje den enkleste iterative metoden for å løse Ax = b Er Jacobi’ S Metode. Merk at enkelheten i denne metoden er både god og dårlig: bra, fordi den er relativt lett å forstå og dermed er en god første smak av iterative metoder; dårlig, fordi den ikke vanligvis brukes i praksis (selv om den potensielle nytten har blitt revurdert med adventen av parallell databehandling). Likevel er det et godt utgangspunkt for å lære om mer nyttige, men mer kompliserte, iterative metoder.
Gitt en nåværende tilnærming
x(k) = (x1(k), x2(k), x3(k), …, xn(k))
For x, Er Strategien Til Jacobis Metode å bruke den første ligningen og de nåværende verdiene til x2(k), x3(k), …, xn(k) for å finne en ny verdi x1(k+1), og på samme måte å finne En ny verdi.en ny verdi xi(k) ved Hjelp av i-Ligningen og de gamle verdiene til de andre variablene. Det vil si, gitt nåværende verdier x(k) = (x1 (k), x2 (k),…, xn(k)), finn nye verdier ved å løse for
x(k+1) = (x1(k+1), x2(k+1),…, xn(k+1))
i
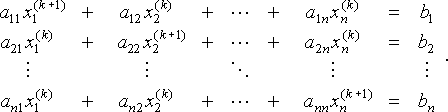
dette systemet kan også skrives som

for å være klar betyr subscript i at xi(k) er det i-elementet av vektor
x(k) = (x1(k), x2(k), …, xi(k), …, xn(k) ),
og hevet k tilsvarer den spesielle iterasjonen (ikke kth-kraften til xi ).
hvis vi skriver D, L og U for diagonalen, streng nedre trekantet og streng øvre trekantet og deler av a, henholdsvis,
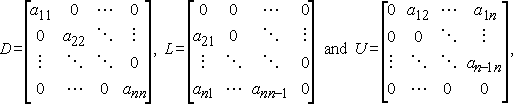
Da Jacobi Metode kan skrives i matrise-vektor notasjon som
Eksempel 1
la Oss bruke Jacobi Metode til systemet
 .
.ved hvert trinn, gitt de nåværende verdiene x1(k), x2(k), x3(k), løser vi for x1(k+1), x2 (k + 1) og x3 (k+1) i
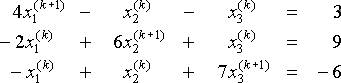 .
.Så, hvis vår første gjetning x(0) = (x1 (0), x2(0), x3 (0)) er nullvektoren 0 = (0,0,0) — en vanlig første gjetning med mindre vi har noen tilleggsinformasjon som fører oss til å velge noen andre — så finner vi x (1) = (x1 (1), x2 (1), x3(1)) ved å løse
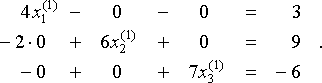
Så x(1) = (x1(1), x2 (1), x3(1)) = (3/4, 9/6, -6/7) ≈ (0.750, 1.500, -0.857). Vi itererer denne prosessen for å finne en sekvens av stadig bedre tilnærminger x(0), x(1), x(2), … . Vi viser resultatene i tabellen under, med alle verdier avrundet til 3 desimaler.
Vi er interessert i feilen e ved hver iterasjon mellom den sanne løsningen x og tilnærmingen x (k): e(k) = x − x(k). Åpenbart vet vi vanligvis ikke den sanne løsningen x. men for å bedre forstå oppførselen til en iterativ metode, er det opplysende å bruke metoden til å løse et system Ax = b som vi kjenner den sanne løsningen og analyserer hvor raskt tilnærmingene konvergerer til den sanne løsningen. For dette eksemplet er den sanne løsningen x = (1, 2, -1).
normen til en vektor ||x|| forteller oss hvor stor vektoren er som helhet(i motsetning til hvor stor hvert element av vektoren er). Vektornormen som oftest brukes i lineær algebra er l2-normen:
for eksempel, hvis x = (1, 2, -1), så
I denne modulen vil vi alltid bruke l2-normen (inkludert for matrisenormer i etterfølgende opplæringsprogrammer), slik at / / / / alltid betyr|| ||2.
for vårt formål observerer vi at / / x / / vil være liten nøyaktig når hver av elementene x1, x2,…, xn i x = (x1, x2,…, xn) er liten. I den følgende tabellen blir feilens norm gradvis mindre ettersom feilen i hvert av de tre elementene x1, x2, x3 blir mindre, eller med andre ord, ettersom tilnærmingene blir gradvis bedre.
| k | x(k) | x(k) − x(k-1) | e (k) = x-x (k) | ||e(k)|| | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.000 | -0.000 | -0.000 | − | − | − | -0.000 | -0.000 | -1.000 | 2.449 |
| 1 | 0.750 | 1.500 | -0.857 | -0.000 | -0.000 | -0.857 | 0.250 | 0.500 | -0.143 | 0.557 |
| 2 | 0.911 | 1.893 | -0.964 | 0.161 | 0.393 | -0.107 | 0.089 | 0.107 | -0.036 | 0.144 |
| 3 | 0.982 | 1.964 | -0.997 | 0.071 | 0.071 | -0.033 | 0.018 | 0.036 | -0.003 | 0.040 |
| 4 | 0.992 | 1.994 | -0.997 | 0.010 | 0.029 | 0.000 | 0.008 | 0.006 | -0.003 | 0.011 |
| 5 | 0.999 | 1.997 | -1.000 | 0.007 | 0.003 | -0.003 | 0.001 | 0.003 | 0.000 | 0.003 |
| 6 | 0.999 | 2.000 | -1.000 | 0.000 | 0.003 | 0.001 | 0.000 | 0.001 | 0.000 | 0.001 |
| 7 | 1.000 | 2.000 | -1.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 8 | 1.000 | 2.000 | -1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |