zie ook
FASTQ files
gemiddelde Q is een slecht idee!
verwachte fouten
Kwaliteitsfiltering
de kwaliteitsscore van een base, ook bekend als een Phred-of Q-score, is een integer waarde die de geschatte kans op een fout weergeeft, d.w.z. dat de base onjuist is. Als P de foutkans is, dan:
P = 10-Q/10
Q = -10 log10(P)
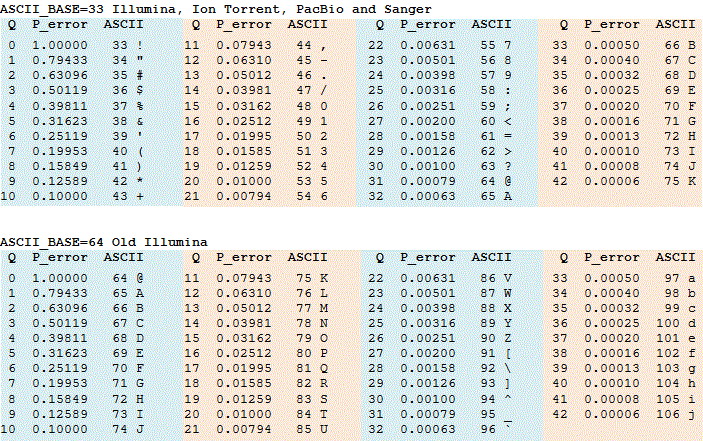
Q-scores worden vaak weergegeven als ASCII-tekens. De regel voor het converteren van een ASCII-teken naar een geheel getal varieert, zie fastq opties voor details. Tabellen die converteren tussen integer Q-scores, ASCII-tekens en foutkansen worden weergegeven in de tabel hieronder ASCII_BASE 33, die nu bijna universeel wordt gebruikt, en ASCII_BASE 64, die wordt gebruikt in sommige oudere Illumina-gegevens.
wat voor soort fout?
er is een belangrijk verschil tussen Q-scores in reads van 454 en Illumina. In feite negeert 454 de mogelijkheid van substitutiefouten en Illumina negeert indels. Met 454 is de Q-score de geschatte kans dat de lengte van het homopolymeer verkeerd is, en met Illumina is de Q-score de kans dat de basisaanroep onjuist is. In het geval van Illumina is dit redelijk omdat indel fouten zeer zeldzaam zijn. Maar met 454 komen substitutiefouten vrij vaak voor, met een vergelijkbare frequentie als homopolymeerfouten. Dit betekent dat 454 Q-scores niet zo informatief zijn als Illumina Q-scores, maar nog steeds nuttig zijn in de praktijk. Zie kwaliteitsfiltering voor verdere discussie.
kleine Q-scores
een Q-score van 3 betekent P = 0.5, wat betekent dat er een 50% kans is dat de basis verkeerd is, en lagere waarden vertegenwoordigen nog hogere kans op fouten. Q = 0 betekent P=1, dat wil zeggen dat de basisaanroep zeker verkeerd is, dus dit wordt zelden gebruikt, hoewel het geschikt zou kunnen zijn voor een onbepaald basis (vaak weergegeven als ‘N’). Ik heb nog nooit een fastq-bestand met Q=0 gezien, maar omdat het formaat niet gestandaardiseerd is, Weet ik het niet zeker. De laagste waarde die gewoonlijk in de praktijk wordt gevonden is Q = 2( P = 0,63), wat betekent dat de basisaanroep eerder fout dan juist is.
herkenning van het formaat
de commando ‘ s fastx_info en fastq_chars kunnen gebruikt worden om het formaat te bepalen. De belangrijkste parameter is ASCII_BASE, die voor zover ik weet altijd 33 of 64 is. Met een typisch bereik van Q2 tot Q40, geeft dit een bereik van ASCII waarden van 35 tot 73 met ASCII_BASE = 33 en van 66 tot 104 met ASCII_BASE=64. Deze bereiken overlappen elkaar van ASCII 66 tot 73. Ook kunnen waarden > Q40 worden geproduceerd door bepaalde machinesoftware en door bepaalde nabewerkingssoftware, zoals gepaarde leesassemblages. Dus als we ASCII waarden >73 zien, betekent dat niet per se dat we ASCII_BASE=64 hebben, dit kunnen hoge kwaliteitsscores zijn met ASCII_BASE=33. De enige manier om zeker te zijn is als we ASCII waarden < 64 zien, in welk geval we weten dat ASCII_BASE=33. Een snelle manier om visueel te controleren is om te zoeken naar # en$, wat ASCII_BASE = 33 betekent of kleine letters die waarschijnlijk ASCII_BASE = 64 impliceren.