varför använda Bland-Altman-tomten
Bland-Altman-tomten kommer från medicinsk industri för att jämföra måttet för två instrument. Det första målet med John Martin Bland & Douglas Altman var att svara på denna fråga :
är de två mätmetoderna tillräckligt överens ? – D. G. ALTMAN och J. M. Intetsägande
om så är fallet betyder det att om du har två instrument där man är toppmodern till en hög kostnad och den andra är 10 gånger billigare, är resultaten som erhållits med den billigaste metoden jämförbara med referensen och kan den ersättas med tillräcklig noggrannhet? Till exempel är hjärtfrekvensen som tillhandahålls av en ansluten klocka på $20 tillräckligt exakt som ett resultat av ett elektrokardiogram ? Det andra målet var att ta fram en metod där resultaten är lättförståeliga för icke-statistiker.
i analytics är A / B-testning (så känd som Champion-Challenger) en vanlig metod för test för att jämföra resultaten av en ny åtgärd / en ny behandling / en ny design / … på population_A till population_B som har den aktuella åtgärden. När vi har testets resultat måste de analyseras och presenteras för ett beslutsteam som mestadels består av icke-statistiker. Det är därför Bland-Altman-tomten är relevant eftersom den kommer att jämföra resultaten från A/B-testet på en plot med alla statistiska åtgärder som visas på ett förståeligt sätt.
i sitt papper visade de också varför korrelationskoefficienten, det statistiska testet av medeljämförelse och regressionen är olämpliga för att besluta om överenskommelse om två åtgärder som skulle vara i vårt A/B-testfall för att besluta om utmanarens kraft jämfört med mästaren.
de data som används
för den här artikeln kommer jag att använda ett dataset tillgängligt på Kaggle (kommer från ett DataCamp-projekt) som heter ”Mobile Games A/B Testing with Cookie Cats”. Länken finns i referensdelen .
Cookie Cats är en populär mobil pusselspel där som spelare framsteg nivåerna, kommer han att stöta på ”grindar” som kommer att tvinga honom att vänta en tid innan du fortsätter att spela eller att göra ett köp. I en sådan bransch är retentionen en av de viktigaste mätvärdena och laget som ansvarar för spelet skulle se effekten om den första porten flyttades från nivå 30 till nivå 40 på retentionen vid 7 dagar. För att se beteendet hos ett sådant drag gjorde de ett A/B-test och de gav oss datauppsättningen av dessa resultat. Vi kommer att se hur Bland-Altman-tomten kommer att svara på följande fråga : ”Hur man analyserar A / B-resultaten på retentionsnivån vid 7 dagar när väntetiden går från nivå 30 till nivå 40 ?”
datasetet består av 90.189 rader där vi har spelarens unika id, A/B-testets version (väntetid vid gate_30 / gate_40), spelrundans summa, retention_1 är ett booleskt ordstäv om spelaren kom tillbaka nästa dag och retention_7 är ett booleskt ordstäv om spelaren kom tillbaka efter 7 dagar. För att få relevanta uppgifter att svara på vår fråga är det nödvändigt att göra lite rengöring. Jag kommer bara att hålla klienten med en retention_1 = True (för om retention_1=False, retention_7 är False också), ett antal spelrundor 30 (för om de inte går till 30, kommer de inte att påverkas av porten) och ett antal spelrundor < 170 (för om vi överväger varaktigheten av ett spel = 5 minuter, om en spelare spelar 2 timmar per dag under 7 dag kommer han att spela 120*7/5 = 168 spel. Ett högre antal skulle betraktas som en anormal användning). Efter detta filter består datasetet av 20.471 rader som Figur1 nedan. Dessutom är datasetet lika balanserat mellan gate_30 & gate_40.

hur byggs Bland-Altman-tomten
vi kommer att se på det här avsnittet Hur man anpassar den ursprungliga Bland-Altman-tomten för att tillämpa den på ett A/B-test. Först och främst kommer jag att förklara hur är tomten byggd i sin ursprungliga version , och sedan kommer jag att förklara hur man bygger den med våra A/B-testdata.
på grund av att den ursprungliga Bland-Altman-tomten jämför mätningen av 2 instrument, har de samma längd genom design. Till exempel, med pulsmätningen mellan $20 connect-klockan och elektrokardiogrammet, tas åtgärden samtidigt med samma förhållanden som leder till samma antal mätningar för 2-metoderna. Så vi kan representera varje dataset rad som en upplevelse som på exemplet i Figuren2 nedan.

det är här vi stöter på den första ”smärtpunkten”. Ett A / B-test betraktas som en unik upplevelse medan vi som vi ser ovan behöver flera upplevelser för att bygga tomten. För att kringgå denna begränsning kommer vi att skapa från A/B-testet flera bootstrapped-prover med båda samma & olika längd.
vi genererar 300 icke-unika slumpmässiga heltal mellan 200 och 1.000. Dessa heltal kommer att representera längden på varje bootstrapped-prov och för att gynna bootstraps statistiska egenskaper dupliceras varje icke-unikt slumpmässigt heltal 50 gånger. Dessa siffror används för att ha en provdiversitet men det är godtyckligt och längden beror på storleken på den ursprungliga datauppsättningen. Dessa 15.000 (300 * 50) bootstrapped prover med en längd mellan 200 och 2.000 erhålls genom ett slumpmässigt urval med en ersättning från den ursprungliga datauppsättningen och de sammanfogas tillsammans. Det kan representeras som Figuren3.
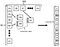
följande kod skapar bootstrapped dataset från originaldata (var försiktig, det kan ta tid eftersom bootstrapped dataset har en längd på 9.184.350 rader {genom att ändra random_state, skulle vi ha i genomsnitt (((200+1.000)/2)*300*50 = 9.000.000 rader}).
sedan grupperar vi efter n_sample (id för varje 15.000 bootstrapped sample), n_sample_2 (längden på varje bootstrapped sample) och version för att få summan av spelarens retention vid 7 dagar per grind som i Figur 4.

vi kan läsa denna utgång som: det bootstrapped sample n 0/14.999 består av 564 rader där 98 spelare fortfarande spelar på 7 dagar med väntetid på gate_30 medan 105 spelare fortfarande spelar på 7 dagar med väntetid på gate_40.
sedan använder vi en statistisk egenskap hos boostrap som säger att medelvärdet av ett bootstrap-prov är en bra uppskattning av det verkliga medelvärdet av en distribution. Vi gör en grupp av n_sample_2 och version för att ha för varje unikt prov Längd det genomsnittliga antalet spelarens retention på 7 dagar per grindar som i Figur 5.

vi kan läsa denna utgång som: när provet har 200 rader finns det i genomsnitt 34,60 spelare som fortfarande spelar på 7 dagar med väntetid på gate_30 medan 34,38 spelare som fortfarande spelar på 7 dagar med väntetid på gate_40.
sedan packar vi upp databasen för att få datauppsättningen i ett tydligare format som Figur6.

i detta skede har vi all nödvändig information för att bygga Bland-Altman-tomten och representationen av dataset är densamma som i Figuren2 ovan.
Bland-Altman-tomten består av 2 axlar. X-axeln är genomsnittet av de två metoderna att jämföra. Så det är för varje rad: (gate_30i + gate_40i) / 2 ||| y-axeln är skillnaden mellan metod A och metod B. Så det är för varje rad: (gate_30i – gate_40i) ||| och här är den andra ”smärtpunkten” vi har. Genom att hålla y-axeln som den är, kommer ökningen av provernas storlek att öka skillnaderna. Som ett resultat kommer den statistiska åtgärden vi kommer att få senare att överviktas av de största proverna. För att kringgå denna begränsning kommer vi att representera y-axeln i procent . För att göra det är beräkningen av y för varje rad: ((gate_30i – gate_40i)*100 / ((gate_30i + gate_40i)/2) ||| datasetet ser ut som Figure7.

vi måste kontrollera att y-axeln är normalt fördelad för att lita på konfidensintervallet som kommer att visas. Du kan bedöma det med hjälp av shapiro-wilk-testet eller åtminstone med ett histogram. Om fördelningen inte är Normal kan du göra en transformation som logaritmisk transformation. I vårt fall anser jag fördelningen som Normal.

Bland-Altman består av 3 linjer (se Figur9):
- medelvärdena för y
- y: s övre gräns för konfidensintervallet (här vid 95% med tanke på 1.96)
- y: s nedre gräns för konfidensintervallet (vid 95%)

vi sätter ihop allt, paketet pyCompare gör det möjligt att rita Bland-Altman-tomten på ett mycket enkelt sätt utan att behöva bygga db:
det tar först metod a (mästaren) och sedan Metod B (utmanaren). Sedan, Om procent = sant, kommer det automatiskt att göra kalkylen vi gjorde ovan. Det finns några andra parametrar som vi kommer att diskutera senare.
hur man tolkar Bland-Altman-tomten för A / B-testet
här är vi ! Här är figuren av Bland-Altman-tomten för A / B-testningen som genereras av koden ovan:

först och främst är medelvärdet och medelvärdet konfidensintervall (ljusblå Rand) annorlunda än 0 (högre i vårt fall). Vilket innebär att retentionsnivån (namngiven bias i originalpapperet) för gate_30 och gate_40 är signifikant olika. På grund av att 2.93 > 0 Det innebär att en > B < — > Champion > Challenger och som ett resultat att en väntetid på gate_30 ger en större retention än en väntetid på gate_40.
de två laxstängerna representerar konfidensintervallet vid 95% (namngiven gräns för överenskommelse i originalpapperet) och säger att vi är övertygade om att 95% av värdena kommer att vara mellan . I vårt exempel är detta mycket kraftfullt eftersom vi kan säga att retentionen av gate_30 nästan alltid kommer att vara större än gate_40.
som du kan se finns det 2 värden ovanför den övre laxremsan och 4 under den nedre, vilket är 6/300 = 0,02 < 0.05 så på grund av att vi är säkra på att 95% av värdena ligger inom 2-gränserna, 5% kan vara över eller under och i vårt fall representerar det 2% då är det helt normalt 😉
i pyCompare-paketet finns parametern limitOfAgreement som syftar till att ändra gränserna för förtroende. Här skulle en relevant fråga vara: ”vid vilken procentandel kan jag vara säker på att retentionen av gate_30 alltid kommer att vara större än gate_40 ?”För att svara på denna fråga måste den lägsta gränsen vara lika med 0, så vi måste hitta rätt värde för att få 0 som vi kan se i koden nedan som ger Figuren11:

vi ser att när limitOfAgreement = 1.55 är gränsen nästan lika med 0. Då måste vi kolla in Normalfördelningstabellen värdet vid 1,55 vilket är 0,9394, så vi är säkra på ((1-0.9394)*2)*100 = 87.88% att retentionen av gate_30 alltid kommer att vara större än den av gate_40
en sista punkt att lägga till är att oavsett medelvärdet av provet, de är enhetligt representerade på tomten vilket innebär att tolkningen vi gör generaliseras oavsett storleken på provet är. Om vi hade sett en slags konisk representation av värdena kunde vi faktiskt dra slutsatsen att provets storlek påverkar resultaten så att vi inte kan ha en giltig Tolkning.
slutsats
vi såg varför det kan vara relevant att använda Bland-Altman-tomten för att få en uppfattning om resultaten av ett A/B-test på en enkel tomt, hur man skapar tomten från ett A/B-test och hur man tolkar det. Detta fungerar bara om skillnaden är normal, men det kommer att vara nödvändigt att omvandla data.
dessutom kollade jag appen och portarna verkar vara på gate_40 medan vi bevisade att retentionen vid 7 dagar var bättre vid 30. I det här fallet visar det sig att retentionen kanske inte är det bästa måttet att följa jämfört med lönsamheten !
D. G. Altman och J. M. Bland, mätning i medicin: analysen av Metodjämförelsestudier, statistikern 32 (1983) 307-317
https://projects.datacamp.com/projects/184 eller https://www.kaggle.com/yufengsui/mobile-games-ab-testing
D. G. Altman och J. M. Bland, statistiska metoder för att bedöma överensstämmelse mellan två metoder för klinisk mätning, The Lancet 327 (1986) 307-310
D. Giavarina, förståelse intetsägande Altman analys, Biochemia Medica 25 (2015) 141-151