Por qué usar la gráfica de Bland-Altman
La gráfica de Bland-Altman proviene de la industria médica para comparar la medida de dos instrumentos. El primer objetivo de John Martin Bland & Douglas Altman era responder a esta pregunta :
¿Coinciden suficientemente los dos métodos de medición ? – D. G. ALTMAN y J. M. BLAND
Si es el caso, significa que si tiene dos instrumentos donde uno es el estado de la técnica a un alto costo y el segundo es 10 veces más barato, ¿los resultados obtenidos por el método más barato son comparables a la referencia y podría reemplazarse con una precisión suficiente? Por ejemplo, ¿la frecuencia cardíaca proporcionada por un reloj conectado de $20 es lo suficientemente precisa como resultado de un electrocardiograma ? El segundo objetivo era elaborar un método en el que los resultados fueran fácilmente comprensibles para los no estadísticos.
En analytics, las pruebas A / B (también conocidas como Champion-Challenger) son una metodología común de prueba para comparar los resultados de una nueva acción / un nuevo tratamiento / un nuevo diseño / popul en population_A con population_B que tiene la acción actual. Una vez que tenemos los resultados de la prueba, tienen que ser analizados y presentados a un equipo de decisión compuesto en su mayoría por no estadísticos. Es por eso que la gráfica de Bland-Altman es relevante porque comparará los resultados de la prueba A/B en una gráfica con todas las medidas estadísticas mostradas de una manera comprensible.
En su artículo, también mostraron por qué el coeficiente de correlación, la prueba estadística de comparación de medias y la regresión son inapropiados para decidir sobre la concordancia de dos medidas que estarían en nuestro caso de prueba A/B para decidir sobre el poder del retador en comparación con el del campeón.
Los datos utilizados
Para este artículo utilizaré un conjunto de datos disponible en Kaggle (procedente de un proyecto de DataCamp) llamado «Pruebas A/B de juegos móviles con Gatos de galletas». El enlace está en la parte de referencias .
Cookie Cats es un popular juego de rompecabezas móvil en el que, a medida que un jugador progresa en los niveles, se encontrará con «puertas» que lo obligarán a esperar un tiempo antes de continuar jugando o hacer una compra. En tal industria, la retención es una de las métricas clave y el equipo a cargo del juego vería el impacto si la primera puerta se moviera del nivel 30 al nivel 40 en la retención a los 7 días. Para ver el comportamiento de tal movimiento, hicieron una prueba A/B y nos proporcionaron el conjunto de datos de estos resultados. Veremos cómo la trama de Bland-Altman responderá a la siguiente pregunta : «¿Cómo analizar los resultados A / B sobre el nivel de retención a los 7 días cuando el tiempo de espera pasa del nivel 30 al nivel 40 ?»
El conjunto de datos se compone de 90.189 filas donde tenemos el id único del jugador, la versión de la prueba A/B (tiempo de espera en gate_30 / gate_40), la suma de las rondas de juego, retention_1 es un dicho booleano si el jugador regresó al día siguiente y retention_7 es un dicho booleano si el jugador regresó después de 7 días. Para tener los datos relevantes para responder a nuestra pregunta, es necesario hacer un poco de limpieza. Solo mantendré al cliente con retention_1 = True (porque si retention_1=False, retention_7 también es False), un número de rondas de juego ≥ 30 (porque si no van hasta 30, no se verán afectados por la puerta) y un número de rondas de juego < 170 (porque si consideramos la duración de un juego = 5 minutos, si un jugador juega 2 horas al día durante 7 días jugará 120*7/5 = 168 juegos. Un número mayor se consideraría un uso anormal). Después de este filtro, el conjunto de datos se compone de 20.471 filas como figura 1 a continuación. Además, el conjunto de datos está equilibrado por igual entre gate_30 & gate_40.

Cómo se construye el gráfico Bland-Altman
Veremos en esta sección cómo adaptar el gráfico Bland-Altman original para aplicarlo a una prueba A/B. En primer lugar , voy a explicar cómo se construye la trama en su versión original, y luego, explicaré cómo construirla con los datos de nuestras pruebas A/B.
Debido a que la gráfica original de Bland-Altman compara la medición de 2 instrumentos, tienen la misma longitud por diseño. Por ejemplo, con la medición de la frecuencia cardíaca entre el reloj connect 20 connect y el electrocardiograma, la medición se realiza al mismo tiempo con las mismas condiciones, lo que lleva a tener el mismo número de mediciones para los 2 métodos. Así que podemos representar la fila de cada conjunto de datos como una experiencia como en el ejemplo de la Figura 2 a continuación.

Aquí es donde encontramos el primer «punto de dolor». Una prueba A / B se considera una experiencia única, mientras que como vemos anteriormente, necesitamos varias experiencias para construir la trama. Para evitar esta limitación, crearemos a partir de la prueba A/B varias muestras bootstrap que tengan la misma & longitud diferente.
Generamos 300 enteros aleatorios no únicos entre 200 y 1.000. Estos enteros representarán la longitud de cada muestra de arranque y, para beneficiar las propiedades estadísticas del arranque, cada entero aleatorio no único se duplica 50 veces. Estos números se utilizan para tener una diversidad de muestras, pero es arbitraria y la longitud depende del tamaño del conjunto de datos original. Estas 15.000 (300*50) muestras bootstrap que tienen una longitud entre 200 y 2.000 se obtienen mediante un muestreo aleatorio con un reemplazo del conjunto de datos original y se concatenan juntas. Se puede representar como la Figura3.
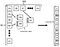
El siguiente código crea el bootstrap conjunto de datos a partir de los datos originales (cuidado, puede lleva tiempo, ya que el bootstrap conjunto de datos tiene una longitud de 9.184.350 filas {cambiando el random_state, tendríamos en promedio (((200+1.000)/2)*300*50 = 9.000.000 filas}).
Luego, agrupamos por n_sample (el id de cada 15.000 muestra de arranque), n_sample_2 (la longitud de cada muestra de arranque) y la versión para tener la suma de la retención del jugador a 7 días por puerta, como en la Figura 4.

podemos leer esta salida como: el bootstrap de la muestra n°0/14.999 se compone de 564 filas donde el 98 jugadores siguen jugando en 7 días, con un tiempo de espera en gate_30 mientras que 105 jugadores siguen jugando en 7 días, con un tiempo de espera en gate_40.
Entonces, usamos una propiedad estadística del boostrap que dice que la media de una muestra de bootstrap es un buen estimador de la media verdadera de una distribución. Hacemos un grupo por n_sample_2 y versión para tener para cada longitud de muestra única el número promedio de retención de jugadores a 7 días por puerta, como en la Figura 5.

Podemos leer esta salida como: cuando la muestra tiene 200 filas, hay un promedio de 34,60 jugadores que siguen jugando a los 7 días con un tiempo de espera en gate_30, mientras que 34,38 jugadores que siguen jugando a los 7 días con un tiempo de espera en gate_40.
Luego descomprimimos la base de datos para tener el conjunto de datos en un formato más claro como la Figura6.

En esta etapa tenemos toda la información necesaria para construir el gráfico de Bland-Altman y la representación del conjunto de datos es el mismo que en la Figura 2 anterior.
La gráfica de Bland-Altman se compone de 2 ejes. El eje x es el promedio de los dos métodos a comparar. Así es para cada fila: (gate_30i + gate_40i ) / 2 ||| El eje y es la diferencia entre el método A y el método B. Así que es para cada fila: (gate_30i-gate_40i) | | | Y aquí está el segundo «punto de dolor» que tenemos. Al mantener el eje y tal como está, el aumento del tamaño de las muestras aumentará la variabilidad de las diferencias. Como resultado, la medida estadística que obtendremos más adelante estará sobre ponderada por las muestras más grandes. Para evitar esta limitación, representaremos el eje y en porcentaje . Para hacerlo, el cálculo de y es para cada fila: ((gate_30i-gate_40i) * 100 / (( gate_30i + gate_40i)/2) | | | El conjunto de datos se parece a la figura 7.

Tenemos que comprobar que el eje y está distribuido normalmente para poder confiar en el intervalo de confianza que se mostrará. Puede evaluarlo usando la prueba de shapiro-wilk o al menos con un histograma. Si la distribución no es normal, puede hacer una transformación como la transformación logarítmica. En nuestro caso, considero que la distribución es Normal.

El Bland-Altman se compone de 3 líneas (ver Figura 9):
- el promedio de los valores de y
- el límite superior del intervalo de confianza (aquí en el 95% dado el 1.96)
- el límite inferior del intervalo de confianza (en 95%)

Que juntamos, el paquete pyCompare permite dibujar la gráfica de Bland-Altman de una manera muy fácil sin tener que construir db:
Primero se necesita el método A (el campeón) y luego el método B (el retador). Entonces, si percentage = True, automáticamente hará el cálculo que hicimos arriba. Hay algunos otros parámetros que discutiremos más adelante.
Cómo interpretar el gráfico de Bland-Altman para la prueba A / B
¡Aquí estamos ! Aquí está la figura de la gráfica de Bland-Altman para las pruebas A/B generadas por el código anterior:

En primer lugar, la media y el intervalo de confianza de la media (franja azul claro) son diferentes de 0 (mayor en nuestro caso). Lo que significa que el nivel de retención (llamado sesgo en el artículo original) de gate_30 y gate_40 son significativamente diferentes. Debido a que 2.93 > 0 significa que un > B < — > Campeón > Retador y, como resultado, un período de espera en gate_30 proporciona una retención mayor que un período de espera en gate_40.
Las dos barras de salmón representan el intervalo de confianza al 95% (límite de acuerdo nombrado en el documento original) diciendo que estamos convencidos de que el 95% de los valores estarán entre . En nuestro ejemplo, esto es muy poderoso porque podemos decir que la retención de gate_30 será casi siempre mayor que la de gate_40.
Como puede ver, hay 2 valores por encima de la franja superior de salmón y 4 por debajo de la inferior, que es 6/300 = 0.02 < 0.05 así que debido a que estamos seguros de que el 95% de los valores están dentro de los 2 límites, el 5% puede estar por encima o por debajo y en nuestro caso representa el 2%, entonces es perfectamente normal 😉
En el paquete pyCompare está el parámetro limitOfAgreement que tiene como objetivo cambiar los límites de confianza. Aquí, una pregunta relevante sería: «¿En qué porcentaje puedo estar seguro de que la retención de gate_30 será siempre mayor que la de gate_40 ?»Para responder a esta pregunta, el límite más bajo tiene que ser igual a 0, por lo que tenemos que encontrar el valor correcto para tener 0, como podemos ver en el código a continuación que proporciona la Figura11:

Vemos que cuando limitOfAgreement = 1.55, el límite es casi igual a 0. Luego tenemos que verificar en la tabla de distribución normal el valor en 1.55, que es 0.9394, por lo que estamos seguros de que ((1-0.9394)*2)*100 = 87.88% que la retención de gate_30 siempre será mayor que la de gate_40
Un último punto a agregar es que cualquiera que sea el valor promedio de la muestra, están representados uniformemente en la gráfica, lo que significa que la interpretación que estamos haciendo está generalizada sea cual sea el tamaño de la muestra. De hecho, si hubiéramos visto una especie de representación cónica de los valores, podríamos concluir que el tamaño de la muestra tiene un impacto en los resultados, por lo que no podemos tener una interpretación válida.
Conclusión
Vimos por qué puede ser relevante usar la gráfica de Bland-Altman para tener una vista sobre los resultados de una prueba A/B en una gráfica simple, cómo crear la gráfica a partir de una prueba A/B y cómo interpretarla. Esto solo funciona en caso de normalidad de la diferencia, sin embargo, será necesario transformar los datos.
Además, comprobé la aplicación y las puertas parecen estar en gate_40, mientras que demostramos que la retención a los 7 días era mejor a los 30. En este caso, muestra que la retención tal vez no sea la mejor métrica a seguir en comparación con la rentabilidad.
D. G. Altman y J. M. Bland, Medición en Medicina: el Análisis de Estudios de Comparación de Métodos, El Estadístico 32 (1983) 307-317
https://projects.datacamp.com/projects/184 O https://www.kaggle.com/yufengsui/mobile-games-ab-testing
D. G. Altman y J. M. Bland, Métodos Estadísticos para Evaluar la Concordancia entre Dos Métodos de Medición Clínica, The Lancet 327 (1986) 307-310
D. Giavarina, Understanding Bland Altman analysis, Biochemia Medica 25 (2015) 141-151