El ensayo de ELISA produce tres tipos diferentes de salida de datos:
Cuantitativos
Los datos de ELISA se pueden interpretar en comparación con una curva estándar (una dilución en serie de un antígeno purificado conocido) para calcular con precisión las concentraciones de antígeno en varias muestras (Figura 6).
Cualitativo
ELISA también se puede utilizar para obtener una respuesta afirmativa o negativa que indique si un antígeno en particular está presente en una muestra, en comparación con un pozo en blanco que no contiene antígeno o un antígeno de control no relacionado.
Semicuantitative
ELISA se puede utilizar para comparar los niveles relativos de antígeno en muestras de ensayo, ya que la intensidad de la señal variará directamente con la concentración de antígeno.
Curva estándar
Los datos ELISA se representan típicamente con densidad óptica vs concentración logarítmica para producir una curva sigmoidal como se muestra en la Figura 6. Las concentraciones conocidas de antígeno se utilizan para producir una curva estándar y, a continuación, estos datos se utilizan para medir la concentración de muestras desconocidas en comparación con la porción lineal de la curva estándar. Esto se puede hacer directamente en el gráfico o con el software de ajuste de curvas que normalmente se encuentra en los lectores de placas ELISA.
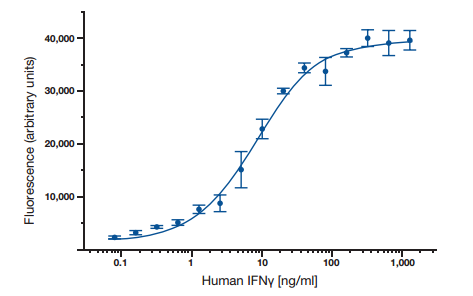
Fig. 6. Una curva estándar ELISA típica.
Modelos de curva de calibración
Si se necesita un resultado cuantitativo, la forma más sencilla de proceder es promediar el triplicado de las lecturas estándar y deducir la lectura de la muestra de control en blanco. A continuación, trace la curva estándar, encuentre la línea de mejor ajuste o, al menos, dibuje una curva de punto a punto para que se pueda determinar la concentración de las muestras. Cualquier dilución que se realice debe ajustarse en esta etapa. Esta es generalmente la medida práctica en la que se puede realizar el cálculo manual.
Una variación es trazar los datos utilizando semi-log, log / log, log / logit y sus derivados, los modelos logísticos de 4 o 5 parámetros. El uso de soluciones basadas en software/automatizadas permite considerar enfoques gráficos más sofisticados. El uso de regresión lineal dentro de un paquete de software agrega varias posibilidades de comprobación más; es posible verificar el valor R2 para determinar la bondad de ajuste general. Para la parte de la curva en la que la relación de concentración a lectura tiene una relación lineal, los valores de R2 >0,99 representan un ajuste muy bueno. La precisión se puede mejorar aún más mediante el uso de concentraciones estándar adicionales en ese rango.
Un aspecto de la gráfica lineal es que comprime los puntos de datos en las concentraciones más bajas de la curva estándar, lo que hace que sea el rango más preciso (el área con más probabilidades de alcanzar el valor R2 requerido). Para contrarrestar esta compresión se puede utilizar un gráfico semi-log; aquí se representa el registro del valor de concentración (en el eje x) contra la lectura (en el eje y). Este método proporciona una curva de datos en forma de S que distribuye más puntos de datos en el patrón sigmoidal más fácil de usar.
El tipo de gráfico log/log (registro de concentración contra registro de lectura) logra linealizar más de la curva de datos. El rango de concentración estándar de baja a media es generalmente lineal en este modelo, solo el extremo superior del rango tiende a inclinarse. El log / logit y sus derivados, los modelos logísticos de 4 o 5 parámetros, son más sofisticados y requieren cálculos y estimaciones más complejos de valores máximos, mínimos, EC50 y de pendiente. El modelo de 5 parámetros requiere además el valor de asimetría.
Si bien estos modelos de curva de calibración pueden ofrecer un rendimiento mejorado, un buen punto de partida sería utilizar el gráfico log-log con una comprobación del porcentaje de recuperación (recuperación de analitos de muestras con puntas). Alternativamente, por lo menos «ajustar» los valores de lectura de la curva estándar, es con frecuencia un enfoque «suficientemente bueno». La forma más sencilla de comprobar es calcular hacia atrás los estándares de calibración y comprobar que se encuentran dentro del 20% del valor nominal de lectura. Una advertencia es no confiar en valores R2 «buenos» y encontrar el modelo de curva de calibración que ofrezca los mejores valores de recuperación para los estándares.
Sensibilidad ELISA
ELISA es uno de los inmunoensayos más sensibles disponibles. El rango de detección típico para un ELISA es de 0,1 a 1 fmol o de 0,01 ng a 0,1 ng, con una sensibilidad que depende de las características particulares de la interacción anticuerpo-antígeno. Además, algunos sustratos, como los que producen señales quimioluminiscentes o fluorescentes mejoradas, se pueden utilizar para mejorar los resultados.
Como se mencionó anteriormente, la detección indirecta producirá niveles más altos de señal y, por lo tanto, debería ser más sensible. Sin embargo, también puede causar una señal de fondo más alta, lo que reduce los niveles de señal específicos de la red.