Why use the Bland-Altman plot
The Bland-Altman plot comes from the medical industry in order to compare the measure for two instruments. O primeiro objectivo de John Martin Bland & Douglas Altman era responder a esta questão :
os dois métodos de medição estão suficientemente de acordo ? – D. G. ALTMAN and J. M. BLAND
Se for o caso, significa que se você tem dois instrumentos, onde um é o estado da arte em um alto custo, e o segundo é 10 vezes mais barato, os resultados obtidos pelo método mais barato são comparáveis aos de referência e poderia ser substituído com uma precisão suficiente? Por exemplo, a frequência cardíaca fornecida por um relógio conectado de 20 dólares é suficientemente precisa como resultado de um eletrocardiograma ? O segundo objectivo era produzir um método em que os resultados fossem facilmente compreensíveis para os não estatísticos.
No google analytics, o teste A/B (também conhecido como Campeão do Challenger) é uma metodologia comum de teste para comparar os resultados de uma ação / um novo tratamento / um novo design / … no population_A para population_B tendo a ação atual. Uma vez que temos os resultados do teste, eles têm que ser analisados e apresentados a uma equipe de decisão composta principalmente por não-estaticistas. É por isso que a parcela Bland-Altman é relevante porque irá comparar os resultados do teste A/B numa parcela com todas as medidas estatísticas apresentadas de uma forma compreensível.
Em seu papel, eles também mostrou qual o coeficiente de correlação, o teste estatístico de média a comparação e a regressão são inadequados para decidir sobre o acordo de duas medidas, que seria o nosso teste A/B caso para decidir sobre o poder do challenger, em comparação com as do campeão.
os dados utilizados
para este artigo utilizarei um conjunto de dados disponível no Kaggle (proveniente de um projecto DataCamp) chamado “Mobile Games A/B Testing with Cookie Cats”. O link está na parte de referências .Cookie Cats é um popular jogo de quebra-cabeça móvel onde, como um jogador progride os níveis, ele vai encontrar “gates” que vai forçá-lo a esperar por algum tempo antes de continuar a jogar ou fazer uma compra. Em tal indústria, a retenção é uma das principais métricas e a equipe responsável pelo jogo veria o impacto se o primeiro portal fosse movido do nível 30 para o nível 40 na retenção de 7 dias. Para ver o comportamento de tal movimento eles fizeram um teste A / B e nos forneceram o conjunto de dados desses resultados. Veremos como a trama Bland-Altman responderá à seguinte pergunta: : “Como analisar os resultados A / B no nível de retenção em 7 dias quando o tempo de espera passa do nível 30 para o nível 40 ?”
O conjunto de dados é composto de 90.189 linhas, onde temos o leitor de id exclusivo, o teste A/B é a versão (tempo de espera no gate_30 / gate_40), o jogo de rodadas de’ soma, retention_1 é um booleano dizendo que se o jogador voltou no dia seguinte e retention_7 é um booleano dizendo que se o jogador voltou, depois de 7 dias. Para ter os dados relevantes para responder à nossa pergunta, é necessário fazer alguma limpeza. Eu só irá manter o cliente ter uma retention_1 = True (porque se retention_1=False, retention_7 é Falso também), um número de rodadas igual ou superior a 30 (porque se eles não vão até 30 anos, eles não serão afetados pela porta) e um número de rondas de jogo < 170 (porque se considerarmos a duração de um jogo = 5 minutos, se um jogador joga 2 horas por dia durante 7 dias, ele vai jogar 120*7/5 = 168 jogos. Um número maior seria considerado como um uso anormal). Após este filtro, o conjunto de dados é composto por 20.471 linhas como Figura 1 abaixo. Além disso, o conjunto de dados é igualmente equilibrado entre gate_30 & gate_40.

How is built the Bland-Altman plot
we will see on this section how to adapt the original Bland-Altman plot in order to apply it to an A / B test. Em primeiro lugar , vou explicar como é que o enredo é construído na sua versão original, e depois, vou explicar como construí-lo com os dados dos nossos testes A/B.
devido ao facto da parcela original de Bland-Altman comparar a medição de 2 instrumentos, eles têm o mesmo comprimento por design. Por exemplo, com a medição da frequência cardíaca entre us $20 ligar o relógio e o eletrocardiograma, a medida é tomada no mesmo horário, com as mesmas condições que levam a ter o mesmo número de medição para os 2 métodos. Assim podemos representar a linha de cada conjunto de dados como uma experiência como no exemplo na Figura 2 abaixo.

é aqui que encontramos o primeiro “ponto de dor”. Um teste A / B é considerado como uma experiência única enquanto, como vemos acima, precisamos de várias experiências para construir o enredo. Para contornar esta limitação, vamos criar a partir do teste A/B várias amostras de inicialização com ambos o mesmo comprimento & diferente.
geramos 300 inteiros aleatórios Não únicos entre 200 e 1000. Estes inteiros representarão o comprimento de cada amostra inicializada e, a fim de beneficiar as propriedades estatísticas do bootstrap, cada inteiro aleatório Não-único é duplicado 50 vezes. Estes números são usados para ter uma diversidade de amostras, mas é arbitrário e o comprimento depende do tamanho do conjunto de dados original. Estas 15.000 (300*50) amostras de arranque com um comprimento entre 200 e 2.000 são obtidas por amostragem aleatória com substituição do conjunto de dados original e são concatenadas em conjunto. Pode ser representado como a Figura 3.
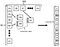
O código a seguir cria o bootstrapped dataset a partir de dados originais (cuidado, ele pode leva tempo, porque o bootstrapped conjunto de dados tem um comprimento de 9.184.350 linhas {alterando o random_state, teríamos, em média,(((200+1.000)/2)*300*50 = 9.000.000 linhas}).
em seguida, agrupamos por n_sample (o id de cada 15.Milhares de amostras bootstrapped), n_sample_2 (o comprimento de cada amostra bootstrapped) e versão, a fim de ter a soma da retenção do jogador a 7 dias por portões, como Na Figura 4.

podemos ler esta saída como: o bootstrapped exemplo n°0/14.999 é composto de 564 linhas onde 98 jogadores ainda estão jogando em 7 dias, com um tempo de espera no gate_30 enquanto 105 jogadores ainda estão jogando em 7 dias, com um tempo de espera no gate_40.
então, nós usamos uma propriedade estatística do boostrap dizendo que a média de uma amostra de bootstrap é um bom estimador da verdadeira média de uma distribuição. Nós fazemos um grupo por n_sample_2 e versão, a fim de ter para cada tamanho de amostra única o número médio de retenção do jogador em 7 dias por portões, como Na Figura 5.

podemos ler esta saída como: quando a amostra tem 200 linhas existem em média 34.60 os jogadores que ainda estão jogando em 7 dias, com um tempo de espera no gate_30 enquanto 34.38 os jogadores que ainda estão jogando em 7 dias, com um tempo de espera no gate_40.
então nós unstack o banco de dados a fim de ter o conjunto de dados em um formato mais claro como a Figura 6.

a parcela Bland-Altman é composta por 2 eixos. O eixo x é a média dos dois métodos a comparar. Assim é para cada linha: (gate_30i + gate_40i) / 2 ||| O eixo y é a diferença entre Um método e método de B. Portanto, ele é, para cada linha: (gate_30i – gate_40i) ||| E aqui está o segundo “ponto de dificuldade” nós temos. Mantendo o eixo y tal como está, o aumento do tamanho das amostras aumentará a variabilidade das diferenças. Como resultado, a medida estatística que iremos obter mais tarde será sobrestimada pelas maiores amostras. Para contornar esta limitação, representaremos o eixo y em porcentagem . Para fazê-lo, o cálculo de y é, para cada linha: ((gate_30i – gate_40i)*100 / (( gate_30i + gate_40i)/2) ||| O conjunto de dados parece Figure7.

temos de verificar se o eixo y é normalmente distribuído, a fim de confiar no intervalo de confiança que será exibido. Você pode avaliá-lo usando o teste shapiro-wilk ou pelo menos com um histograma. Se a distribuição não é Normal, então você pode fazer uma transformação como a transformação logarítmica. No nosso caso, considero a distribuição Normal.

o Bland-Altman é composto por 3 linhas (ver Figura 9):
- média dos valores de y
- y do limite superior do intervalo de confiança (aqui a 95%, dada a 1.96)
- y do limite inferior do intervalo de confiança (em 95%)

reunimos todos, o pacote pyCompare permite desenhar o gráfico Bland-Altman de uma forma muito fácil sem ter de construir db:
é preciso primeiro o método A (o campeão) e depois o método B (o desafiante). Então, se percentual = verdadeiro, ele fará automaticamente o cálculo que fizemos acima. Há outros parâmetros que discutiremos mais tarde.
como interpretar a trama Bland-Altman para o teste A / B
aqui estamos ! Aqui está a figura da plotagem de Bland-Altman para o teste A/B gerado pelo código acima:

em primeiro lugar, o intervalo de confiança médio e médio (faixa azul claro) são diferentes de 0 (superior no nosso caso). O que significa que o nível de retenção (nomeado viés no papel original) de gate_30 e gate_40 são significativamente diferentes. Devido a 2.93 > 0 isso significa que a > B < — > Champion > Challenger e como resultado que um período de espera em gate_30 proporciona uma retenção maior do que um período de espera em gate_40.
as duas barras de salmão representam o intervalo de confiança de 95% (nomeado limite de acordo no artigo original), dizendo que estamos convencidos de que 95% dos valores serão entre . No nosso exemplo, isto é muito poderoso, porque podemos dizer que a retenção de gate_30 será quase sempre maior do que a de gate_40.
como pode ver, existem 2 valores acima da faixa superior do salmão e 4 abaixo da faixa inferior, que é 6/300 = 0, 02 < 0.05 de modo devido, que estamos certos de que 95% dos valores estão dentro de 2 limites, 5% pode ser acima ou abaixo e no nosso caso, representa 2% então é perfeitamente normal 😉
No pyCompare pacote há o parâmetro limitOfAgreement que visa alterar os limites de confiança. Aqui, uma pergunta relevante seria : “em que porcentagem posso ter certeza de que a retenção do gate_30 será sempre maior do que a do gate_40 ?”Para responder a esta questão, o menor limite tem que ser igual a 0, então temos de encontrar o valor correto para ter 0, como podemos ver no código abaixo que fornecem a Afigura11:

Nós vemos que quando limitOfAgreement = 1.55, o limite é quase igual a 0. Então temos que verificar na tabela de distribuição Normal o valor em 1,55 que é 0,9394, então estamos certos de ((1-0.9394)*2)*100 = 87.88% que a retenção de gate_30 sempre será maior do que a de gate_40
Um último ponto a acrescentar é que qualquer que seja o valor médio da amostra, eles são uniformemente representados no gráfico, o que significa que a interpretação que estamos a fazer são generalizadas seja qual for o tamanho da amostra. Na verdade, se tivéssemos visto uma espécie de representação Cónica dos valores, poderíamos ter concluído que o tamanho da amostra tem um impacto nos resultados, pelo que não podemos ter uma interpretação válida.
conclusão
vimos porque é que pode ser relevante usar a trama Bland-Altman para ter uma visão sobre os resultados de um teste A/B numa simples parcela, como criar a parcela a partir de um teste A/B e como interpretá-la. Isto só funciona em caso de normalidade da diferença no entanto, será necessário transformar os dados.Além disso, verifiquei a aplicação e os portões parecem estar em gate_40, enquanto provámos que a retenção aos 7 dias era melhor aos 30. Neste caso, mostra que a retenção não é talvez a melhor métrica a seguir em comparação com a rentabilidade !
D. G. Altman e J. M. Branda, Medição em Medicina: a Análise do Método de Comparação de Estudos, O Estatístico 32 (1983) 307-317
https://projects.datacamp.com/projects/184 OU https://www.kaggle.com/yufengsui/mobile-games-ab-testing
D. G. Altman e J. M. Branda, de Métodos Estatísticos para Avaliar a Concordância entre Dois Métodos de avaliação Clínica, O Lancet 327 (1986) 307-310
D. Giavarina, de Compreensão, de Bland Altman análise, Biochemia Medica 25 (2015) 141-151