Forse il metodo iterativo più semplice per risolvere Ax = b è il Metodo di Jacobi. Si noti che la semplicità di questo metodo è sia buona che cattiva: buona, perché è relativamente facile da capire e quindi è un buon primo assaggio dei metodi iterativi; cattiva, perché non è tipicamente utilizzata nella pratica (sebbene la sua potenziale utilità sia stata riconsiderata con l’avvento del calcolo parallelo). Tuttavia, è un buon punto di partenza per conoscere metodi iterativi più utili, ma più complicati.
Dato una corrente di approssimazione
x(k) = (x1(k) x2(k), x3(k), …, xn(k))
per x, la strategia di Jacobi Metodo è quello di utilizzare la prima equazione e i valori di corrente di x2(k), x3(k), …, xn(k) per trovare un nuovo valore di x1(k+1), e, analogamente, per trovare un nuovo valore xi(k) utilizzando i th equazione e i vecchi valori di altre variabili. Che, date le attuali valori di x(k) = (x1(k) x2(k), …, xn(k)), trovare nuovi valori, risolvendo
x(k+1) = (x1(k+1), x2(k+1), …, xn(k+1))
in
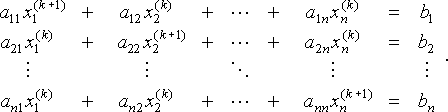
Questo sistema può anche essere scritto come

Per essere chiari, il pedice i indica che xi(k) è il mi esimo elemento del vettore
x(k) = (x1(k) x2(k), …, xi(k), …, xn(k) ),
e esponente k corrisponde alla iterazione (non kth di potere di xi ).
Se scriviamo D, L e U per la diagonale, rigoroso triangolare inferiore e rigoroso superiore triangolare e parti di A, rispettivamente,
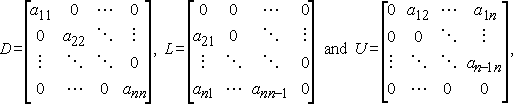
quindi il Metodo di Jacobi può essere scritto in matrice-vettore di notazione
Esempio 1
proviamo ad applicare il Metodo di Jacobi per il sistema
 .
.Ad ogni passo, dati i valori correnti x1(k), x2 (k), x3(k), risolviamo per x1(k+1), x2(k+1) e x3 (k+1) in
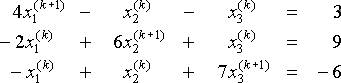 .
.Quindi, se la nostra ipotesi iniziale x(0) = (x1(0), x2(0), x3(0)) è il vettore zero 0 = (0,0,0) — una comune ipotesi iniziale a meno che non ci hanno alcune informazioni aggiuntive che ci porta a scegliere qualche altro, non possiamo che trovare x(1) = (x1(1), x2(1), x3(1) ), risolvendo
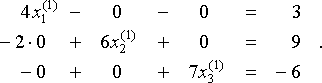
Quindi, x(1) = (x1(1), x2(1), x3(1)) = (3/4, 9/6, -6/7) ≈ (0.750, 1.500, -0.857). Iteriamo questo processo per trovare una sequenza di approssimazioni sempre migliori x (0), x(1), x(2),…. Mostriamo i risultati nella tabella seguente, con tutti i valori arrotondati a 3 cifre decimali.
Siamo interessati all’errore e ad ogni iterazione tra la vera soluzione x e l’approssimazione x (k): e(k) = x − x(k) . Ovviamente, di solito non conosciamo la vera soluzione x. Tuttavia, per comprendere meglio il comportamento di un metodo iterativo, è illuminante usare il metodo per risolvere un sistema Ax = b per il quale conosciamo la vera soluzione e analizziamo quanto velocemente le approssimazioni convergono alla vera soluzione. Per questo esempio, la vera soluzione è x = (1, 2, -1).
La norma di un vettore ||x|| ci dice quanto è grande il vettore nel suo insieme (al contrario di quanto è grande ogni elemento del vettore). La norma vettoriale più comunemente usata nell’algebra lineare è la norma l2:
Ad esempio, se x = (1, 2, -1), quindi
In questo modulo, useremo sempre la norma l2 (anche per le norme della matrice nei tutorial successivi), in modo che / / / / significhi sempre|| ||2.
Per i nostri scopi, osserviamo che ||x|| sarà piccolo esattamente quando ciascuno degli elementi x1, x2, …, xn in x = (x1, x2, …, xn ) è piccolo. Nella tabella seguente, la norma dell’errore diventa progressivamente più piccola man mano che l’errore in ciascuno dei tre elementi x1, x2, x3 diventa più piccolo, o in altre parole, man mano che le approssimazioni diventano progressivamente migliori.
| k | x(k) | x(k) − x(k-1) | e(k) = x − x(k) | ||e(k)|| | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.000 | -0.000 | -0.000 | − | − | − | -0.000 | -0.000 | -1.000 | 2.449 |
| 1 | 0.750 | 1.500 | -0.857 | -0.000 | -0.000 | -0.857 | 0.250 | 0.500 | -0.143 | 0.557 |
| 2 | 0.911 | 1.893 | -0.964 | 0.161 | 0.393 | -0.107 | 0.089 | 0.107 | -0.036 | 0.144 |
| 3 | 0.982 | 1.964 | -0.997 | 0.071 | 0.071 | -0.033 | 0.018 | 0.036 | -0.003 | 0.040 |
| 4 | 0.992 | 1.994 | -0.997 | 0.010 | 0.029 | 0.000 | 0.008 | 0.006 | -0.003 | 0.011 |
| 5 | 0.999 | 1.997 | -1.000 | 0.007 | 0.003 | -0.003 | 0.001 | 0.003 | 0.000 | 0.003 |
| 6 | 0.999 | 2.000 | -1.000 | 0.000 | 0.003 | 0.001 | 0.000 | 0.001 | 0.000 | 0.001 |
| 7 | 1.000 | 2.000 | -1.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 8 | 1.000 | 2.000 | -1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |