z výše uvedeného diagramu řetězce klasifikátorů je znázorněno. Téměř se podobá datové struktuře „LinkedList“. Y1, Y2..Yᴺ jsou proměnné odezvy každého klasifikátoru (bude to 0 nebo 1). Odpovědi ze všech předchozích klasifikátorů (kromě 1.) jsou naočkovány do dalšího klasifikátoru a tyto se stávají prvky spolu s původními vstupními prvky (f1..Fischer).
obecně platí, že klasifikátor K bude postaven s kompletní sadou vstupních funkcí: f1,f2,..fⁿ, Y1, Y2,..Yᴷ⁻1
Teď, tady jedna otázka je, „Jak pořadí třídění řetězce je rozhodnuto ?“Existují různé strategie, jak je uvedeno níže :
soubor klasifikačních řetězců (ECC): zde se používá model klasifikace souborů. Jsou vybrány náhodné vzorky řetězců a na nich je postaven soubor. Předpokládaný výstup přichází použitím většinového hlasovacího schématu na výstupech souboru. Je to úplně stejné jako RandomForest classifier.
klasifikační řetězce Monte-Carlo (MCC): Používá metodu Monte-Carlo pro optimální generování sekvencí klasifikátorů.
existují i jiné metody, jako je náhodné vyhledávání nebo metody závislostí pro klasifikátory, ale nejsou příliš běžné.
výstup z každého klasifikátoru bude zachycen jako binární schéma Relevance a na konci určí štítky tříd.
Label Power-set Scheme
základní koncept binárního klasifikačního řetězce & je víceméně stejný. Label power-set funguje jiným způsobem. Považuje každou kombinaci štítků v datovém souboru školení za samostatný štítek. Například pro problém s více štítky třídy 3 budou 100, 001, 101, 111 atd. považovány za samostatné štítky.
Obecně platí, že třída-prostor dimenze N, může existovat 2ᴺ žádné z celkových možných kombinací štítků.
nerozkládá se tedy na žádné dílčí problémy, ale přímo předpovídá kombinaci štítků tříd jako celku.
výhody & nevýhody každého schématu
binární Relevance je jednoduché schéma, snadno implementovatelné. Nepovažuje však označení za závislost, a proto může často nesprávně interpretovat skryté datové vztahy.
klasifikační řetězec dokonale zpracovává vztahy se štítky tříd. Zejména pro případy, kdy některé třídy štítky jsou sub-štítky druhých a výskyt jedné třídy label je silně závislá na jiné štítky(rodič-dítě vztahy ve třídě štítky. Podřízený štítek může nastat, pokud je tam rodičovský štítek). Ale toto schéma je složité povahy a trpí vysokou dimenzionality problém, pokud třída prostor je velký.
Label power-set funguje dobře pro případy, kdy žádná z různých kombinací štítků tříd není menší. Je to velmi jednoduché schéma ve srovnání s binárním relevantním & klasifikačním řetězcem .
ve všech případech je před přijetím rozhodnutí pro konkrétní schéma vyžadováno porozumění datové sadě.
Přesnost Metriky
V multi-class nebo binární single-label problém klasifikace, absolutní přesnost je dána poměrem (bez údajů případů správně klasifikovaných / celkový počet dat instance).
podívejme se na scénář případu s více štítky pomocí našeho příkladu datové sady. Pokud je otázka s id 241465 klasifikována štítky: „modelování“, „centrální limitní věta“, „stupně volnosti“, co můžeme říci? Skutečné štítky tříd v datovém souboru byly „statistická významnost“, „modelování“, „centrální limitní věta“, „stupně svobody“ a „falešná korelace“. Ani to není úplně špatná předpověď, ani to není úplně správné. Pokud půjdeme na tradiční správnou metriku přesnosti založenou na celkovém poměru, rozhodně nebudeme schopni posoudit klasifikátor. Potřebujeme něco, abychom posoudili částečnou správnost klasifikátoru s více značkami.
Hamming Loss Metrické
Místo počítání počet správně klasifikovaných dat instance, Hamming Loss počítá ztráty generované v bit string třídy štítky během předpověď. To XOR operace mezi původní binární řetězec třídy štítky a předpověděl třídy štítky pro instance data a vypočítá průměr přes dataset. Jeho exprese je dána
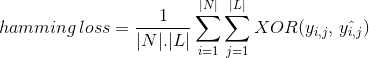
kde
|N| = počet instancí datových
|L| = mohutnost třídy prostoru
yᵢ,ⱼ = skutečná úroveň označení j v datové instance
^yᵢ,ⱼ = předpověděl trochu třídy označení j v datové instanci jsem
‚hamming loss hodnota se pohybuje od 0 do 1. Protože se jedná o ztrátovou metriku, její interpretace má na rozdíl od normálního poměru přesnosti opačnou povahu. Menší hodnota ztráty hammingu naznačuje lepší klasifikátor.
přesnost podmnožiny
existují situace, kdy můžeme jít o absolutní poměr přesnosti, kde je důležité měřit přesnou kombinaci předpovědí štítků. Může to znít relevantně v případě „power-set Label“. Ve scénáři s více štítky, to je známé jako přesnost podmnožiny.
Kromě těchto dvou může být přesnost každého jednotlivého binárního klasifikátoru posuzována jinými tradičními metrikami, jako je poměr přesnosti, skóre F1, přesnost, odvolání atd.
Toto je vše o teoretickém modelování pro klasifikaci s více štítky. V dalším článku uvidíme případovou studii využívající skutečná data. Kód průzkumu dat je k dispozici na Githubu.
Nedávno jsem napsal knihu o ML (https://twitter.com/bpbonline/status/1256146448346988546)