z powyższego diagramu przedstawiono łańcuch klasyfikatorów. Prawie przypomina strukturę danych „LinkedList”. Y1, Y2..Yᴺ są zmiennymi odpowiedzi każdego klasyfikatora (będzie to 0 LUB 1). Odpowiedzi wszystkich poprzednich klasyfikatorów (z wyjątkiem 1st) są zaszczepiane do następnego klasyfikatora, a te stają się funkcjami wraz z oryginalnymi funkcjami wejściowymi (f1..fⁿ).
ogólnie rzecz biorąc, klasyfikator K będzie zbudowany z kompletnym zestawem funkcji wejściowych: f1,f2,..fⁿ,Y1,Y2,..Yᴷ⁻1
teraz, tutaj przychodzi tylko jedno pytanie: „jak zakon klasyfikator łańcuch zdecydował ?”Istnieją różne strategie tego, jak podano poniżej :
Ensemble of Classifier chains ( ECC): tutaj używany jest Ensemble model klasyfikacji. Losowe próbkowanie łańcuchów są wybierane i zespół jest zbudowany na tym. Przewidywany wynik pochodzi z zastosowania systemu większości głosów na wyjścia zespołu. Jest zupełnie taki sam jak randomforest classifier.
Łańcuchy klasyfikacyjne Monte-Carlo (MCC): Stosuje metodę Monte-Carlo do optymalnego generowania sekwencji klasyfikatorów.
istnieją inne metody, takie jak wyszukiwanie losowe lub metody zależności dla klasyfikatorów, ale nie są zbyt powszechne w użyciu.
wyjście z każdego klasyfikatora będzie przechwytywane jak binarny schemat istotności i określi etykiety klas na końcu.
schemat potęgowania etykiet
podstawowe pojęcie binarnej istotności & łańcucha klasyfikatora jest mniej więcej takie samo. Label power-set działa w inny sposób. Każda kombinacja etykiet w zestawie danych szkoleniowych jest traktowana jako osobna Etykieta. Na przykład w przypadku 3-klasowego problemu z wieloma etykietami, 100, 001, 101, 111 itd.będą uważane za oddzielne etykiety.
ogólnie rzecz biorąc, przestrzeń klasy o wymiarze N, może być 2ᴺ no wszystkich możliwych kombinacji etykiet.
więc nie rozkłada się na żadne podproblemy, ale bezpośrednio przewiduje kombinację etykiet klas jako całości.
zalety& wady każdego schematu
Znaczenie binarne jest prostym schematem, łatwym do wdrożenia. Nie bierze jednak pod uwagę zależności między etykietami i dlatego często może błędnie interpretować Ukryte relacje danych.
łańcuch klasyfikatorów doskonale radzi sobie z relacjami z etykietami klas. Szczególnie w przypadku, gdy niektóre etykiety klas są pod-etykietami innych, a występowanie jednej etykiety klasy jest w dużym stopniu zależne od innych etykiet(relacje rodzic-dziecko w etykietach klas. Etykieta dziecka może wystąpić iff Etykieta rodzica jest tam). Ale ten schemat ma złożony charakter i cierpi na problem wysokiej wymiarowości, jeśli przestrzeń klasy jest duża.
Label power-set działa dobrze w przypadkach, gdy liczba różnych kombinacji etykiet klas jest mniejsza. Jest to bardzo prosty schemat w porównaniu z łańcuchem Klasyfikującym Znaczenie binarne &.
we wszystkich przypadkach zrozumienie zbioru danych jest wymagane przed podjęciem decyzji dla określonego schematu.
wskaźniki dokładności
w przypadku wielu klas lub binarnych problemów z klasyfikacją pojedynczej etykiety, dokładność bezwzględna jest określona przez stosunek (liczba instancji danych prawidłowo sklasyfikowanych / całkowita liczba instancji danych).
zobaczmy scenariusz dla przypadku wielu etykiet na podstawie naszego przykładowego zestawu danych. Jeśli pytanie o id 241465 jest zaklasyfikowane z etykietami: „modelowanie”, „twierdzenie o Centralnej granicy”, „stopnie swobody”, to co możemy powiedzieć? Rzeczywiste etykiety klas w zbiorze danych były „istotność statystyczna”, „modelowanie”, „Central-limit-theorem”, „stopnie-of-freedom” i „spurious-correlation”. Ani nie jest to całkowicie błędne przewidywanie, ani nie jest całkowicie słuszne. Jeśli zdecydujemy się na tradycyjną metrykę dokładności opartej na współczynniku poprawności względem całkowitej, na pewno nie będziemy w stanie ocenić klasyfikatora. Potrzebujemy czegoś, co oceni częściową poprawność klasyfikatora wielu etykiet.
Hamming Loss Metric
zamiast liczyć liczbę poprawnie sklasyfikowanych instancji danych, Hamming Loss oblicza straty wygenerowane w łańcuchu bitów etykiet klas podczas przewidywania. Wykonuje operację XOR pomiędzy oryginalnym binarnym ciągiem etykiet klas i przewidywanymi etykietami klas dla instancji danych i oblicza średnią w całym zbiorze danych. Jego wyrażenie jest podane przez
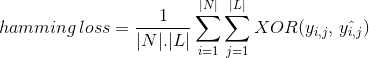
gdzie
|n| = liczba instancji danych
|L| = cardinalność przestrzeni klas
yᵢ,ⱼ = rzeczywisty bit etykiety klasy j w instancji danych i
^yᵢ,predicted = przewidywany bit etykiety klasy j w instancji danych i
’wartość straty Hamminga waha się od 0 do 1. Ponieważ jest to metryka strat, jej interpretacja ma charakter Odwrotny w przeciwieństwie do normalnego współczynnika dokładności. Mniejsza wartość straty Hamminga wskazuje na lepszą klasyfikację.
dokładność podzbiorów
istnieją sytuacje, w których możemy wybrać bezwzględny współczynnik dokładności, w których ważne jest mierzenie dokładnej kombinacji przewidywań etykiet. Może to brzmieć w przypadku „Label power-set”. W scenariuszu multi-label jest znany jako dokładność podzbiorów.
oprócz tych dwóch, dokładność każdego klasyfikatora binarnego może być oceniana na podstawie innych tradycyjnych wskaźników, takich jak współczynnik dokładności, wynik F1, precyzja, przypomnienie itp.
chodzi o teoretyczne modelowanie klasyfikacji wielowarstwowej. W następnym artykule zobaczymy studium przypadku wykorzystujące rzeczywiste dane. Kod eksploracji danych jest dostępny na Github.
ostatnio jestem autorem książki o ML (https://twitter.com/bpbonline/status/1256146448346988546)