fra ovenstående diagramkæde af klassifikatorer vises. Det ligner næsten ‘LinkedList’ datastruktur. Y1, Y2..Y-kur er responsvariablerne for hver klassifikator (det vil være 0 eller 1). Svar fra alle tidligere klassifikatorer (undtagen 1.) sås i den næste klassifikator, og disse bliver funktioner sammen med originale inputfunktioner(f1..f-kr.).
generelt, klassifikator K vil blive bygget med komplet input feature sæt : f1,f2,..f kr, Y1, Y2,..Yᴷ⁻1
Nu, her et spørgsmål kommer, “Hvordan rækkefølgen af klassificeringen kæden er besluttet ?”Der er forskellige strategier for dette som angivet nedenfor :
Ensemble af Klassificeringskæder ( ECC): Ensemblemodel for klassificering bruges herovre. Tilfældig prøveudtagning af kæder vælges, og et ensemble er bygget oven på dette. Forudsagt output kommer ved at anvende flertalsafstemningsordningen på ensembleudgangene. Det er helt samme som RandomForest classifier.
Monte Carlo Klassificeringskæder (MCC): Det gælder Monte Carlo metode til optimal klassificering sekvens generation.
Der er andre metoder som tilfældig søgning eller afhængighedsmetoder til klassifikatorer, men ikke meget almindelige i brug.
output fra hver klassifikator vil blive fanget som det binære Relevansskema og vil bestemme klasseetiketter i slutningen.
Etiketstrømsætskema
det grundlæggende koncept for den binære relevans & Klassificeringskæde er mere eller mindre det samme. Label effekt-sæt fungerer på en anden måde. Den betragter hver kombination af etiketter i træningsdatasættet som en separat etiket. For et 3-klasse multi-label problem vil 100, 001, 101, 111 osv.
generelt, et klasserum med dimension N, der kan være 2 liter ingen af de samlede mulige etiketkombinationer.
så det nedbrydes ikke til nogen underproblemer, men det forudsiger direkte kombinationen af klassemærker som helhed.
fordele & ulemper ved hver ordning
binær relevans er en simpel ordning, nem at implementere. Men det betragter ikke etiketten som afhængighed og kan derfor ofte fejlagtigt fortolke skjulte datarelationer.
klassificeringskæden håndterer perfekt klasseetiketforhold. Især i tilfælde, hvor nogle klasseetiketter er undermærker for andre, og forekomsten af en klasseetiket er stærkt afhængig af andre etiketter(forhold mellem forældre og barn i klasseetiketter. Børneetiket kan forekomme, hvis forældreetiketten er der). Men denne ordning er kompleks i naturen og lider af høj dimensionalitet problem, hvis klasse rummet er stort.
Label effekt-sæt fungerer godt for tilfælde, hvor ingen af forskellige kombinationer af klasse etiketter er mindre. Det er meget en ligetil ordning sammenlignet med den binære relevans & Klassificeringskæde.
i alle tilfælde kræves datasætforståelse, før der træffes beslutning om en bestemt ordning.
Nøjagtighedsmålinger
i multi-klasse eller binært single-label klassificeringsproblem gives absolut nøjagtighed af forholdet (antal dataforekomster korrekt klassificeret / samlet antal dataforekomster).
lad os se scenariet for multi-label-sagen ved hjælp af vores eksempel datasæt. Hvis spørgsmål med id 241465 er klassificeret med etiketter:’ modellering’,’ central-limit-sætning’,’ frihedsgrader’, hvad kan vi så sige? Faktiske klassemærkater i datasættet var ‘statistisk betydning’, ‘modellering’, ‘central-grænse-sætning’, ‘frihedsgrader’og’ falsk korrelation’. Hverken det er helt forkert forudsigelse eller det er helt rigtigt. Hvis vi går efter traditionel korrekt vs total ratio baseret nøjagtighedsmåling, vil vi bestemt ikke være i stand til at bedømme klassificeringsenheden. Vi har brug for noget for at bedømme den delvise rigtighed af en multi-label klassifikator.
Hamming Loss Metric
i stedet for at tælle Nej af korrekt klassificerede datainstanser beregner Hamming Loss tab genereret i bitstrengen af klasseetiketter under forudsigelse. Det virker mellem den oprindelige binære streng af klasseetiketter og forudsagte klasseetiketter for en datainstans og beregner gennemsnittet på tværs af datasættet. Dens udtryk er givet af
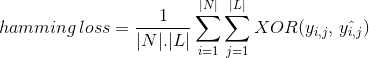
hvor
|N| = antal dataforekomster
|L| = Kardinalitet af klasserum
y-kur,kur = faktisk bit af klassetiket j i dataforekomst i
^y-kur, kur = forudsagt bit af klassetiket j i dataforekomst i
‘hamming loss’ værdi varierer fra 0 til 1. Da det er en tabsmetrik, er dens fortolkning omvendt i modsætning til normalt nøjagtighedsforhold. Mindre værdi af hamming tab indikerer en bedre klassifikator.
Undersætnøjagtighed
Der er nogle situationer, hvor vi kan gå efter et absolut nøjagtighedsforhold, hvor måling af den nøjagtige kombination af etiketforudsigelser er vigtig. Det kan lyde relevant i’ Label strøm-sæt ‘ tilfælde. I multi-label-scenariet er det kendt som undersæt nøjagtighed.
bortset fra disse to kan hver enkelt binær klassificeringsnøjagtighed bedømmes ud fra andre traditionelle målinger som nøjagtighedsforhold, F1-score, præcision, tilbagekaldelse osv.
dette handler om teoretisk modellering til klassificering af flere mærker. Vi vil se en casestudie ved hjælp af reelle data i den næste artikel. Dataefterforskningskoden er tilgængelig på Github.
for nylig skrev jeg en bog om ML (https://twitter.com/bpbonline/status/1256146448346988546)