din diagrama de mai sus este prezentat lanțul de clasificatori. Aproape seamănă cu structura de date LinkedList. Y1, Y2..Y XV sunt variabilele de răspuns ale fiecărui clasificator (va fi 0 sau 1). Răspuns de la toate clasificatori anterioare(cu excepția 1) sunt însămânțate în următorul clasificator și acestea devin caracteristici împreună cu caracteristici de intrare originale (f1..F din art.
în general, clasificator K va fi construit cu set complet de caracteristici de intrare: f1, f2,..F,Y1,Y2,..Yᴷ⁻1
Acum, aici vine întrebarea, „Cât de ordine de clasificator lanț este decis ?”Există diferite strategii pentru acest lucru, așa cum este prezentat mai jos :
ansamblul lanțurilor de Clasificatoare ( ECC): modelul de clasificare al ansamblului este utilizat aici. Eșantionarea aleatorie a lanțurilor sunt selectate și un ansamblu este construit pe partea de sus a acesteia. Rezultatul prezis vine prin aplicarea schemei de vot majoritar asupra rezultatelor ansamblului. Este destul de aceeași ca randomforest clasificator.
lanțuri Clasificatoare Monte-Carlo (MCC): Se aplică metoda Monte-Carlo pentru generarea optimă a secvenței de clasificator.
există și alte metode, cum ar fi Căutarea aleatorie sau metodele de dependență pentru clasificatori, dar nu foarte frecvente în utilizare.
ieșirea din fiecare clasificator va fi capturată ca schema de relevanță binară și va determina etichetele clasei la sfârșit.
schema de setare a puterii etichetei
conceptul fundamental al relevanței binare & lanțul Clasificatorului este mai mult sau mai puțin același. Eticheta power-set funcționează într-un mod diferit. Acesta consideră fiecare combinație de etichete din setul de date de formare ca o etichetă separată. De exemplu, pentru o problemă multi-etichetă de 3 clase, 100, 001, 101, 111, etc vor fi considerate etichete separate.
în general, o clasă-spațiu de dimensiune N, nu poate fi 2 nu de combinații totale posibile de etichete.
deci, nu se descompune în subprobleme, ci prezice direct combinația etichetelor de clasă în ansamblu.
avantaje & dezavantaje ale fiecărei scheme
relevanța binară este o schemă simplă, ușor de implementat. Dar nu ia în considerare interdependența etichetei și, prin urmare, poate interpreta greșit relațiile de date ascunse.
lanțul Clasificatorului gestionează perfect relațiile etichetelor de clasă. În special, pentru cazurile în care unele etichete de clasă sunt sub-etichete ale altora și apariția unei etichete de clasă depinde în mare măsură de alte etichete(relațiile părinte-copil în etichetele de clasă. Eticheta copilului poate apărea dacă eticheta părinte este acolo). Dar această schemă este complexă în natură și suferă de o problemă de dimensionalitate ridicată dacă spațiul de clasă este mare.
eticheta power-set funcționează bine pentru cazurile în care nu de combinații diferite de etichete de clasă este mai mică. Este foarte o schemă simplă în comparație cu relevanța binară & lanț clasificator.
în toate cazurile, înțelegerea seturilor de date este necesară înainte de a lua o decizie pentru o anumită schemă.
măsurători de precizie
în problema clasificării cu mai multe clase sau binare cu o singură etichetă, precizia absolută este dată de raportul (nr de instanțe de date clasificate corect / nr total de instanțe de date).
să vedem scenariul pentru cazul cu mai multe etichete folosind setul nostru de date exemplu. Dacă întrebarea cu id 241465 este clasificată cu etichete:’ modelare’,’ teorema centrală-limită’,’ grade-de-libertate ‘ atunci ce putem spune? Etichetele de clasă reale din setul de date erau ‘semnificație statistică’, ‘modelare’, ‘teoremă limită centrală’, ‘grade-de-libertate’ și ‘corelație falsă’. Nici nu este o predicție complet greșită, nici nu este complet corectă. Dacă mergem pentru metrica de precizie tradițională corectă față de raportul total, cu siguranță nu vom putea judeca clasificatorul. Avem nevoie de ceva pentru a judeca corectitudinea parțială a unui clasificator cu mai multe etichete.
Hamming pierdere Metric
în loc de numărare nu de instanță date clasificate corect, Hamming pierdere calculează pierderea generată în șirul de biți de etichete de clasă în timpul predicție. Funcționează XOR între șirul binar original de etichete de clasă și etichetele de clasă prezise pentru o instanță de date și calculează media din setul de date. Expresia sa este dată de
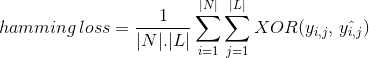
unde
|n| = numărul de instanțe de date
|L| = cardinalitatea spațiului de clasă
y_fixt ,_fixt = bitul real al etichetei de clasă j în instanța de date i
^y_fixt ,_fixt = bitul prezis al etichetei de clasă j în instanța de date i
^ y_fixt ,_fixt = bitul prezis al etichetei de clasă j în instanța de date i
‘valoarea pierderii hamming variază de la 0 la 1. Deoarece este o metrică de pierdere, interpretarea sa este inversă în natură, spre deosebire de raportul normal de precizie. Valoarea mai mică a pierderii hamming indică un clasificator mai bun.
precizia subsetului
există unele situații în care putem merge pentru un raport de precizie absolută în care măsurarea combinației exacte a predicțiilor etichetelor este importantă. Poate părea relevant În cazul’ set de alimentare cu etichetă’. În scenariul cu mai multe etichete, este cunoscut sub numele de precizie subset.
în afară de aceste două, precizia fiecărui clasificator binar individual poate fi evaluată prin alte valori tradiționale, cum ar fi raportul de precizie, scorul F1, precizia, rechemarea etc. și curbele ROC.
este vorba despre modelarea teoretică pentru clasificarea pe mai multe etichete. Vom vedea un studiu de caz folosind date reale în articolul următor. Codul de explorare a datelor este disponibil la Github.
recent am scris o carte despre ML (https://twitter.com/bpbonline/status/1256146448346988546)