De la cadena de clasificadores del diagrama anterior. Casi se asemeja a la estructura de datos de la lista de enlaces. Y1, Y2..y are son las variables de respuesta de cada clasificador (será 0 o 1). Las respuestas de todos los clasificadores anteriores (excepto el 1er) se siembran en el siguiente clasificador y se convierten en características junto con las características de entrada originales (f1..fⁿ).
En general, el clasificador K se construirá con un conjunto de funciones de entrada completo : f1,f2,..f f, Y1, Y2,..Yᴷ⁻1
Ahora, aquí una pregunta que viene, «Cómo el orden de la clasificación de la cadena está decidido ?»Hay diferentes estrategias para esto, como se indica a continuación :
Conjunto de cadenas clasificadoras (ECC): El modelo de clasificación del conjunto se utiliza aquí. Se seleccionan muestras aleatorias de cadenas y se construye un conjunto encima de esto. La salida prevista viene aplicando el esquema de votación por mayoría en las salidas del conjunto. Es bastante igual que el clasificador randomForest.
Cadenas clasificadoras de Monte Carlo (MCC): Aplica el método de Monte Carlo para una generación óptima de secuencias de clasificadores.
Hay otros métodos como Búsqueda aleatoria o métodos de dependencia para clasificadores, pero no son muy comunes en su uso.
La salida de cada clasificador se capturará como el Esquema de Relevancia Binaria y determinará las etiquetas de clase al final.
Esquema de conjunto de energía de etiqueta
El concepto fundamental de la cadena clasificadora de Relevancia Binaria & es más o menos el mismo. Label power-set funciona de una manera diferente. Considera cada combinación de etiquetas en el conjunto de datos de entrenamiento como una etiqueta separada. Por ejemplo, para un problema de etiquetas múltiples de 3 clases, 100, 001, 101, 111, etc. se considerarán etiquetas separadas.
En general, un espacio de clase de dimensión N, puede haber 2 no no de combinaciones de etiquetas posibles totales.
Por lo tanto, no se descompone en ningún subproblema, sino que predice directamente la combinación de etiquetas de clase en su conjunto.
Ventajas & Desventajas de cada esquema
La relevancia binaria es un esquema simple, fácil de implementar. Pero no tiene en cuenta la interdependencia de la etiqueta y, por lo tanto, a menudo puede malinterpretar las relaciones de datos ocultas.
La cadena clasificadora maneja perfectamente las relaciones de las etiquetas de clase. Especialmente, para los casos en los que algunas etiquetas de clase son subetiquetas de otras y la aparición de una etiqueta de clase depende en gran medida de otras etiquetas(relaciones padre-hijo en las etiquetas de clase. La etiqueta del hijo puede ocurrir si la etiqueta del padre está allí). Pero este esquema es de naturaleza compleja y sufre de un problema de alta dimensionalidad si el espacio de clase es grande.
El conjunto de alimentación de etiquetas funciona bien para casos en los que no hay combinaciones diferentes de etiquetas de clase menores. Es un esquema muy sencillo en comparación con la cadena clasificadora de relevancia binaria &.
En todos los casos, es necesario comprender el conjunto de datos antes de tomar una decisión para un esquema en particular.
Métricas de precisión
En el problema de clasificación de etiquetas únicas binarias o multiclase, la precisión absoluta viene dada por la relación (no de instancias de datos clasificadas correctamente / no total de instancias de datos).
Veamos el escenario para el caso de etiquetas múltiples utilizando nuestro conjunto de datos de ejemplo. Si la pregunta con id 241465 se clasifica con etiquetas: ‘modelado’, ‘teorema del límite central’, ‘grados de libertad’, ¿qué podemos decir? Las etiquetas de clase reales en el conjunto de datos eran ‘significación estadística’, ‘modelado’, ‘teorema de límite central’, ‘grados de libertad’ y ‘correlación espuria’. Ni es una predicción completamente equivocada ni es completamente correcta. Si optamos por la métrica tradicional de precisión basada en la relación correcta vs total, definitivamente no podremos juzgar el clasificador. Necesitamos algo para juzgar la corrección parcial de un clasificador de etiquetas múltiples.
Métrica de pérdida de Hamming
En lugar de contar el número de instancias de datos correctamente clasificadas, Hamming Loss calcula la pérdida generada en la cadena de bits de las etiquetas de clase durante la predicción. Realiza operaciones XOR entre la cadena binaria original de etiquetas de clase y las etiquetas de clase previstas para una instancia de datos y calcula el promedio de todo el conjunto de datos. Su expresión está dada por
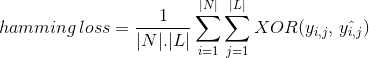
donde
/ L / = cardinalidad del espacio de clase
y=, = = bit real de etiqueta de clase j en la instancia de datos i
^y^, ^ = bit previsto de etiqueta de clase j en la instancia de datos i
‘el valor de hamming loss varía de 0 a 1. Como es una métrica de pérdida, su interpretación es de naturaleza inversa a diferencia de la relación de precisión normal. Un valor menor de pérdida de hamming indica un mejor clasificador.
Precisión de subconjuntos
Hay algunas situaciones en las que podemos buscar una relación de precisión absoluta en las que medir la combinación exacta de predicciones de etiquetas es importante. Puede sonar relevante en el caso de «Conjunto de alimentación de etiqueta». En el escenario de etiquetas múltiples, se conoce como precisión de subconjunto.
Aparte de estos dos, la precisión de cada clasificador binario individual se puede juzgar por otras métricas tradicionales como la relación de precisión, la puntuación F1, la Precisión, el Recuerdo, etc. y las curvas ROC.
Se trata de un modelado teórico para la clasificación de etiquetas múltiples. Veremos un estudio de caso usando datos reales en el siguiente artículo. El código de exploración de datos está disponible en Github.
Recientemente escribí un libro sobre ML (https://twitter.com/bpbonline/status/1256146448346988546)