Dal diagramma precedente viene mostrata la catena di classificatori. Assomiglia quasi alla struttura dei dati “LinkedList”. S1, S2..y are sono le variabili di risposta di ciascun classificatore (sarà 0 o 1). La risposta di tutti i classificatori precedenti (tranne il 1°) viene seminata nel classificatore successivo e queste diventano funzionalità insieme alle funzionalità di input originali (f1..f f).
In generale, il classificatore K verrà creato con un set di funzionalità di input completo: f1, f2,..F1,S1,S2,..Yᴷ⁻1
Ora, qui una domanda, “Come l’ordine di classificazione catena è deciso ?”Ci sono diverse strategie per questo come indicato di seguito :
Ensemble of Classifier chains (ECC): Qui viene utilizzato il modello di ensemble di classificazione. Campionamento casuale di catene sono selezionati e un insieme è costruito su questo. L’output previsto viene applicato lo schema di voto a maggioranza sulle uscite dell’ensemble. È abbastanza simile al classificatore RandomForest.
Catene di classificatori Monte-Carlo (MCC): Applica il metodo Monte-Carlo per la generazione di sequenze di classificatori ottimali.
Esistono altri metodi come la ricerca casuale o i metodi di dipendenza per i classificatori, ma non molto comuni in uso.
L’output di ciascun classificatore verrà catturato come lo schema di rilevanza binaria e determinerà le etichette di classe alla fine.
Label Power-set Scheme
Il concetto fondamentale della Rilevanza binaria & Classificatore catena è più o meno lo stesso. Label power-set funziona in modo diverso. Considera ogni combinazione di etichette nel set di dati di formazione come un’etichetta separata. Ad esempio, per un problema multi-etichetta di 3 classi, 100, 001, 101, 111, ecc.
In generale, uno spazio di classe di dimensione N, ci possono essere 2 no no di combinazioni di etichette possibili totali.
Quindi, non si decompone in alcun sottoproblema, ma predice direttamente la combinazione di etichette di classe nel suo complesso.
Vantaggi & Svantaggi di ogni schema
La rilevanza binaria è uno schema semplice, facile da implementare. Ma non considera l’etichetta interdipendenza e quindi può spesso interpretare erroneamente le relazioni di dati nascosti.
La catena di classificatori gestisce perfettamente le relazioni delle etichette di classe. In particolare, nei casi in cui alcune etichette di classe sono sottoetichette di altre e l’occorrenza di un’etichetta di classe dipende fortemente da altre etichette(relazioni padre-figlio nelle etichette di classe. L’etichetta figlio può verificarsi se l’etichetta genitore è presente). Ma questo schema è di natura complessa e soffre di un problema di alta dimensionalità se lo spazio di classe è grande.
Label power-set funziona bene per i casi in cui nessuna delle diverse combinazioni di etichette di classe è inferiore. È uno schema molto semplice rispetto alla catena di classificatori di rilevanza binaria &.
In tutti i casi, è necessaria la comprensione del set di dati prima di prendere una decisione per un particolare schema.
Metriche di accuratezza
Nel problema di classificazione multi-classe o binario a etichetta singola, l’accuratezza assoluta è data dal rapporto (numero di istanze di dati classificate correttamente / numero totale di istanze di dati).
Vediamo lo scenario per il caso multi-etichetta usando il nostro set di dati di esempio. Se la domanda con id 241465 è classificata con etichette: ‘modeling’, ‘central-limit-theorem’, ‘degrees-of-freedom’ allora cosa possiamo dire? Le etichette di classe effettive nel set di dati erano “significatività statistica”, “modellazione”, “teorema del limite centrale”, “gradi di libertà” e “correlazione spuria”. Né è una previsione completamente sbagliata né è completamente giusta. Se andiamo per la tradizionale metrica di precisione basata sul rapporto corretto vs totale, sicuramente non saremo in grado di giudicare il classificatore. Abbiamo bisogno di qualcosa per giudicare la correttezza parziale di un classificatore multi-etichetta.
Hamming Loss Metrica
Invece di contare no di istanza di dati classificati correttamente, Hamming Loss calcola la perdita generata nella stringa di bit di etichette di classe durante la previsione. Esegue l’operazione XOR tra la stringa binaria originale di etichette di classe e le etichette di classe previste per un’istanza di dati e calcola la media nel set di dati. La sua espressione è data da
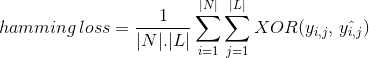
dove
|N| = numero di istanze di dati
|L| = cardinalità di spazio di classe
yᵢ,ⱼ = bit di etichetta di classe j in data istanza i
^yᵢ,ⱼ = predetto bit di etichetta di classe j, con i dati di esempio
‘hamming perdita di valore varia da 0 a 1. Poiché è una metrica di perdita, la sua interpretazione è inversa in natura a differenza del normale rapporto di precisione. Il valore minore della perdita di hamming indica un classificatore migliore.
Precisione del sottoinsieme
Ci sono alcune situazioni in cui possiamo optare per un rapporto di precisione assoluto in cui misurare l’esatta combinazione di previsioni di etichette è importante. Può sembrare rilevante nel caso “Label power-set”. Nello scenario multi-etichetta, è noto come precisione sottoinsieme.
Oltre a questi due, la precisione di ogni singolo classificatore binario può essere giudicata da altre metriche tradizionali come il rapporto di precisione, il punteggio F1, la precisione, il richiamo, ecc.
Si tratta di modellazione teorica per la classificazione multi-etichetta. Vedremo un caso di studio utilizzando dati reali nel prossimo articolo. Il codice di esplorazione dei dati è disponibile su Github.
Recentemente ho scritto un libro su ML (https://twitter.com/bpbonline/status/1256146448346988546)