上の図から分類子のチェーンを示します。 それはほとんど’LinkedList’データ構造に似ています。 Y1、Y2。.Yᴺは各分類器の応答変数です(0または1になります)。 前のすべての分類子(1番目を除く)からの応答は次の分類子にシードされ、これらは元の入力フィーチャとともにフィーチャになります(f1..fⅱ)。
一般に、分類器Kは完全な入力フィーチャセットf1、f2、を使用して構築されます。.fⁿ,Y1,Y2,..Yᴷ⁻1
今、ここに一つの質問に対して付属していますが、”どのように分類器チェーンが決まりますか?”以下に示すように、これにはさまざまな戦略があります:
分類器チェーンのアンサンブル(ECC):分類のアンサンブルモデルは、ここで使用されています。 チェーンのランダムサンプリングが選択され、アンサンブルがこの上に構築されます。 予測された出力は、アンサンブル出力に多数決方式を適用することによって得られます。 それはRandomForest分類子とまったく同じです。
モンテカルロ分類器チェーン(MCC): 最適な分類器シーケンス生成にモンテカルロ法を適用した。
分類子のランダム検索や依存関係メソッドのような他のメソッドがありますが、あまり一般的ではありません。
各分類子からの出力は、バイナリ関連スキームのようにキャプチャされ、最後にクラスラベルが決定されます。
ラベルパワーセットスキーム
バイナリ関連性&分類器チェーンの基本的な概念は、多かれ少なかれ同じです。 ラベルpower-setは別の方法で動作します。 トレーニングデータセット内の各ラベルの組み合わせは、個別のラベルと見なされます。 たとえば、3クラスのマルチラベル問題の場合、100、001、101、111などは別々のラベルと見なされます。
一般に、次元Nのクラス空間は、可能なラベルの組み合わせの合計が2≤noである可能性があります。
だから、それは任意のサブ問題に分解しませんが、それは直接全体としてクラスラベルの組み合わせを予測します。
利点&各スキームの欠点
バイナリ関連性は、実装が簡単なシンプルなスキームです。 しかし、ラベル間の依存関係を考慮していないため、隠されたデータ関係を誤って解釈することがよくあります。
分類子チェーンは、クラスラベルの関係を完全に処理します。 特に、あるクラスラベルが他のクラスラベルのサブラベルであり、あるクラスラベルの発生が他のラベル(クラスラベルの親子関係)に大きく依存する場 子ラベルは、親ラベルがある場合に発生する可能性があります)。 しかし、このスキームは本質的に複雑であり、クラス空間が大きい場合、高次元の問題に苦しんでいます。
Label power-setは、クラスラベルの異なる組み合わせのnoが少ない場合に適しています。 これは、バイナリ関連性&分類子チェーンと比較して非常に簡単なスキームです。
すべてのケースで、特定のスキームの決定を下す前にデータセットの理解が必要です。
精度指標
マルチクラスまたはバイナリ単一ラベル分類問題では、絶対精度は比率(正しく分類されたデータインスタンスの数/データインスタンスの合計
サンプルデータセットを使用して、マルチラベルケースのシナリオを見てみましょう。 Id241465の質問がラベルで分類されている場合:「モデリング」、「中央限界定理」、「自由度」私たちは何を言うことができますか? データセット内の実際のクラスラベルは、「統計的有意性」、「モデリング」、「中央限界定理」、「自由度」、および「スプリアス相関」でした。 それは完全に間違った予測でもなく、完全に正しいものでもありません。 私たちが伝統的な正しい対総比率ベースの精度メトリックのために行くならば、間違いなく私たちは分類器を判断することができません。 マルチラベル分類器の部分的な正しさを判断するために何かが必要です。
Hamming Loss Metric
Hamming Lossは、正しく分類されたデータインスタンスのnoをカウントする代わりに、予測中にクラスラベルのビット列に生成された損失を計算します。 これは、クラスラベルの元のバイナリ文字列とデータインスタンスの予測クラスラベルとの間でXOR演算を行い、データセット全体の平均を計算します。 その表現は次のように与えられます
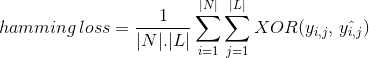
ここで、
|N|=データインスタンスの数
|L|=クラス空間の基数
yᵢ、λ=データインスタンスiのクラスラベルjの実際のビット
^Yᵢ、λ=データイン
‘ハミング損失の値の範囲は0から1です。 これは損失指標であるため、通常の精度比とは異なり、その解釈は本質的に逆です。 ハミング損失の値が小さいほど、分類器が優れていることを示します。
サブセット精度
ラベル予測の正確な組み合わせを測定することが重要な絶対精度比を求める状況がいくつかあります。 それは”ラベルの電源セット”の場合に関連するように聞こえるかもしれません。 マルチラベルシナリオでは、サブセット精度と呼ばれます。
これら二つとは別に、個々のバイナリ分類器の精度は、精度比、F1スコア、精度、リコールなどとROC曲線のような他の伝統的な指標によって判断すること
これは、すべてのマルチラベル分類のための理論的モデリングについてです。 次の記事では、実際のデータを使用したケーススタディを見ていきます。 データ探索コードはGithubで入手できます。
最近私はMLに関する本を執筆しました(https://twitter.com/bpbonline/status/1256146448346988546)