À partir de la chaîne de classificateurs du diagramme ci-dessus est illustrée. Cela ressemble presque à la structure de données « LinkedList ». A1, A2..Y are sont les variables de réponse de chaque classificateur (ce sera 0 ou 1). Les réponses de tous les classificateurs précédents (sauf le 1er) sont ensemencées dans le classificateur suivant et celles-ci deviennent des caractéristiques avec les caractéristiques d’entrée d’origine (f1..fⁿ).
En général, le classificateur K sera construit avec un ensemble complet de fonctionnalités d’entrée: f1, f2,..Fⁿ, Y1, Y2, ..Yᴷ⁻1
Maintenant, voici une question qui me vient, « Comment l’ordre de la classificateur de la chaîne est décidé ? »Il existe différentes stratégies pour cela, comme indiqué ci-dessous :
Ensemble de chaînes de classificateurs (ECC): Le modèle de classification d’ensemble est utilisé ici. L’échantillonnage aléatoire des chaînes est sélectionné et un ensemble est construit en plus de cela. La sortie prévue provient de l’application du système de vote à la majorité sur les sorties d’ensemble. C’est tout à fait la même chose que le classificateur RandomForest.
Chaînes de classement Monte-Carlo (MCC): Il applique la méthode de Monte-Carlo pour une génération optimale de séquences de classificateurs.
Il existe d’autres méthodes comme la recherche aléatoire ou les méthodes de dépendance pour les classificateurs, mais pas très courantes.
La sortie de chaque classificateur sera capturée comme le Schéma de pertinence binaire et déterminera les étiquettes de classe à la fin.
Schéma de puissance d’étiquette
Le concept fondamental de la chaîne de classification de Pertinence binaire & est plus ou moins le même. Le power-set d’étiquettes fonctionne d’une manière différente. Il considère chaque combinaison d’étiquettes dans l’ensemble de données de formation comme une étiquette distincte. Par exemple, pour un problème multi-étiquettes à 3 classes, 100, 001, 101, 111, etc. seront considérés comme des étiquettes séparées.
En général, un espace-classe de dimension N, il peut y avoir 2 no aucune des combinaisons d’étiquettes possibles.
Ainsi, il ne se décompose pas en sous-problèmes, mais prédit directement la combinaison des étiquettes de classe dans son ensemble.
Avantages & Inconvénients de chaque schéma
La pertinence binaire est un schéma simple, facile à mettre en œuvre. Mais il ne considère pas l’interdépendance de l’étiquette et peut donc souvent mal interpréter les relations de données cachées.
La chaîne de classificateurs gère parfaitement les relations d’étiquettes de classe. En particulier, dans les cas où certaines étiquettes de classe sont des sous-étiquettes d’autres et où l’occurrence d’une étiquette de classe dépend fortement d’autres étiquettes (relations parent-enfant dans les étiquettes de classe. L’étiquette enfant peut se produire si l’étiquette parent est là). Mais ce schéma est de nature complexe et souffre d’un problème de dimensionnalité élevé si l’espace de classe est grand.
Le power-set d’étiquettes fonctionne bien dans les cas où aucune combinaison différente d’étiquettes de classe n’est inférieure. C’est un schéma très simple par rapport à la chaîne de classificateurs de pertinence binaire &.
Dans tous les cas, la compréhension de l’ensemble de données est nécessaire avant de prendre une décision pour un schéma particulier.
Métriques de précision
Dans un problème de classification multi-classes ou binaire à étiquette unique, la précision absolue est donnée par le rapport (nombre d’instances de données correctement classées / nombre total d’instances de données).
Voyons le scénario pour le cas multi-étiquettes en utilisant notre exemple de jeu de données. Si la question avec l’id 241465 est classée avec des étiquettes: ‘modélisation’, ‘théorème de limite centrale’, ‘degrés de liberté’ alors que pouvons-nous dire? Les étiquettes de classe réelles dans l’ensemble de données étaient « signification statistique », « modélisation », « théorème de limite centrale », « degrés de liberté » et « corrélation fausse ». Ni ce n’est une prédiction complètement fausse ni ce n’est tout à fait juste. Si nous optons pour une métrique de précision traditionnelle basée sur le rapport correct vs total, nous ne pourrons certainement pas juger le classificateur. Nous avons besoin de quelque chose pour juger de l’exactitude partielle d’un classificateur multi-étiquettes.
Métrique de perte de Hamming
Au lieu de compter le nombre d’instances de données correctement classées, la perte de Hamming calcule la perte générée dans la chaîne de bits des étiquettes de classe pendant la prédiction. Il effectue une opération XOR entre la chaîne binaire d’origine des étiquettes de classe et les étiquettes de classe prédites pour une instance de données et calcule la moyenne sur l’ensemble de données. Son expression est donnée par
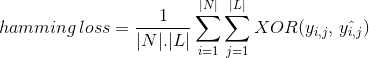
où
| L /= cardinalité de l’espace de classe
yᵢ, bit = bit réel de l’étiquette de classe j dans l’instance de données i
^yy,^ = bit prédit de l’étiquette de classe j dans l’instance de données i
‘ la valeur de la perte de hamming varie de 0 à 1. Comme il s’agit d’une mesure de perte, son interprétation est de nature inverse contrairement au rapport de précision normal. Une valeur moindre de la perte de hamming indique un meilleur classificateur.
Précision du sous-ensemble
Il existe certaines situations où nous pouvons opter pour un rapport de précision absolu où la mesure de la combinaison exacte des prédictions d’étiquettes est importante. Cela peut sembler pertinent dans le cas de l’étiquette power-set. Dans le scénario multi-étiquettes, on parle de précision de sous-ensemble.
En dehors de ces deux, la précision de chaque classificateur binaire individuel peut être jugée par d’autres métriques traditionnelles telles que le rapport de précision, le score F1, la Précision, le Rappel, etc. et les courbes ROC.
Il s’agit d’une modélisation théorique pour la classification multi-étiquettes. Nous verrons une étude de cas utilisant des données réelles dans le prochain article. Le code d’exploration des données est disponible sur Github.
Récemment, j’ai écrit un livre sur le ML (https://twitter.com/bpbonline/status/1256146448346988546)