uit het bovenstaande diagram keten van classificeerders wordt weergegeven. Het lijkt bijna op ‘LinkedList’ datastructuur. Y1, Y2..Yᴺ zijn de responsvariabelen van elke classifier (het zal 0 of 1 zijn). Antwoord van alle vorige classifiers (behalve 1st) worden gezaaid in de volgende classifier en deze worden functies samen met de originele invoer functies(f1..fⁿ).
in het algemeen zal classifier K worden gebouwd met volledige input feature set: f1,f2,..fⁿ,Y1, Y2,..Yᴷ⁻1
Nu, hier is een vraag komt, “Hoe is de volgorde van de classifier keten is besloten ?”Er zijn verschillende strategieën voor dit zoals hieronder gegeven:
Ensemble of Classifier chains (ECC): Ensemble model van classificatie wordt hier gebruikt. Willekeurige bemonstering van ketens worden geselecteerd en een ensemble is gebouwd op de top van deze. Voorspelde output komt door het toepassen van de meerderheid stemschema op de ensemble uitgangen. Het is heel hetzelfde als RandomForest classifier.
Monte-Carlo Classificatieketens (MCC): Het past Monte-Carlo methode toe voor optimale classificatiesequentiegeneratie.
er zijn andere methoden zoals Random Search of dependency methods voor classifiers, maar niet erg gebruikelijk in gebruik.
de uitvoer van elke classifier zal worden vastgelegd zoals het binaire relevantie schema en zal klassenlabels aan het einde bepalen.
Label Power-set schema
het fundamentele concept van de binaire relevantie & Classificatieketen is min of meer hetzelfde. Label power-set werkt op een andere manier. Het beschouwt elke combinatie van labels in de trainingsdataset als een afzonderlijk label. Bijvoorbeeld, voor een 3-klasse multi-label probleem, 100, 001, 101, 111, enz.worden beschouwd als afzonderlijke labels.
in het algemeen, een klasse-ruimte van dimensie N, kunnen er 2ᴺ no van totaal mogelijke labelcombinaties zijn.
dus, het valt niet uiteen in subproblemen, maar het voorspelt direct de combinatie van klassenlabels als geheel.
voordelen & nadelen van elk schema
binaire relevantie is een eenvoudig schema, eenvoudig te implementeren. Maar het houdt geen rekening met het label onderlinge afhankelijkheid en kan dus vaak verborgen Data relaties verkeerd interpreteren.
de classificatieketen is perfect geschikt voor klassenetiketrelaties. Vooral in gevallen waarin sommige klassenetiketten sublabels zijn van andere en het voorkomen van een klasse-label sterk afhankelijk is van andere labels(ouder-kind relaties in klassenetiketten. Kinderlabel kan optreden iff ouderlabel is er). Maar dit schema is complex van aard en lijdt aan hoge dimensionaliteit probleem als klasse ruimte is groot.
Label power-set werkt goed voor gevallen waarin geen verschillende combinaties van klassenetiketten minder is. Het is een zeer eenvoudig schema in vergelijking met de binaire relevantie & Classificatieketen.
in alle gevallen is inzicht in de dataset vereist alvorens een beslissing te nemen voor een bepaald schema.
nauwkeurigheid
in multi-class of binaire single-label classificatie probleem, absolute nauwkeurigheid wordt gegeven door de verhouding (aantal gegevens instanties correct geclassificeerd / totaal aantal gegevens instanties).
laten we eens kijken naar het scenario voor de multi-label case met behulp van onze voorbeelddataset. Als vraag met id 241465 wordt geclassificeerd met labels: ‘modellering’,’ centrale-limietstelling’,’ graden-van-vrijheid’, wat kunnen we dan zeggen? Werkelijke klassenlabels in de dataset waren ‘statistische significantie’, ‘modellering’, ‘centrale-limietstelling’, ‘vrijheidsgraden’ en ‘onechte-correlatie’. Noch het is volledig verkeerde voorspelling, noch het is volledig goed. Als we gaan voor traditionele correcte vs totale verhouding gebaseerde nauwkeurigheid metrische, zeker zullen we niet in staat zijn om de classifier te beoordelen. We hebben iets nodig om de gedeeltelijke juistheid van een multi-label classifier te beoordelen.
Hamming Loss Metric
in plaats van het tellen van het aantal correct geclassificeerde gegevens instantie, Hamming Loss berekent verlies gegenereerd in de bit string van klasse labels tijdens de voorspelling. Het doet XOR-bewerking tussen de oorspronkelijke binaire reeks klassenlabels en voorspelde klassenlabels voor een gegevensinstantie en berekent het gemiddelde over de dataset. De uitdrukking wordt gegeven door
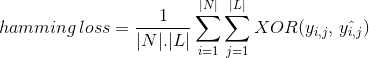
waar
|N| = aantal gegevens exemplaren
|L| = kardinaliteit van de klasse ruimte
yᵢ,ⱼ = werkelijke beetje klasse label j in gegevens exemplaar i
^yᵢ,ⱼ = voorspelde beetje klasse label j in de gegevens zo ben ik
‘hamming verlies’ – waarde varieert van 0 tot 1. Omdat het een verlies-metriek is, is zijn interpretatie omgekeerd van aard in tegenstelling tot de normale nauwkeurigheidsverhouding. Lagere waarde van hamming verlies geeft een betere classifier.
Subsetnauwkeurigheid
er zijn enkele situaties waarin we kunnen gaan voor een absolute nauwkeurigheidsverhouding waarbij het meten van de exacte combinatie van etiketvoorspellingen belangrijk is. Het kan relevant klinken in het geval van “Label power-set”. In het multi-label scenario staat het bekend als subset nauwkeurigheid.
afgezien van deze twee, kan de nauwkeurigheid van elke afzonderlijke binaire classificeerder worden beoordeeld aan de hand van andere traditionele metrics zoals nauwkeurigheidsratio, F1-score, precisie, Recall, enz.en ROC-curven.
dit gaat allemaal over theoretische modellering voor multi-label classificatie. We zullen een casestudy zien met behulp van echte gegevens in het volgende artikel. De data exploration code is beschikbaar op Github.
onlangs schreef ik een boek over ML (https://twitter.com/bpbonline/status/1256146448346988546)