a partir da cadeia de diagramas acima dos Classificadores é mostrado. Quase se assemelha à estrutura de dados “LinkedList”. Y1, Y2..Yᴺ são as variáveis de resposta de cada classificador (será 0 ou 1). Resposta de todos os classificadores anteriores (exceto 1º) são semeados para o classificador seguinte e estes se tornam características juntamente com as características de entrada originais(f1..fⁿ).
em geral, o classificador K será construído com um conjunto completo de características de entrada: f1,f2,..fⁿ,Y1,Y2,..Yᴷ⁻1
Agora, aqui, uma pergunta que vem, “Como a ordem de classificação cadeia é decidido ?”Existem diferentes estratégias para isso como indicado abaixo :
Ensemble of Classifier chains ( ECC): Ensemble of classification is used over here. A amostragem aleatória de cadeias é selecionada e um conjunto é construído em cima disso. A produção prevista resulta da aplicação do sistema de votação por maioria nas saídas globais. É igual ao RandomForest classifier.Cadeias classificadoras de Monte Carlo (MCC): Aplica o método de Monte-Carlo para a geração de sequência de classificação ideal.
existem outros métodos como pesquisa aleatória ou métodos de dependência para classificadores, mas não muito comuns em uso.
a saída de cada classificador será capturada como o esquema de relevância binária e irá determinar etiquetas de classe no final.
Label Power-set Scheme
the fundamental concept of the Binary Relevance & Classifier chain is more or less the same. A etiqueta power-set funciona de uma forma diferente. Considera cada combinação de rótulos no conjunto de dados de formação como um rótulo separado. Por exemplo, para um problema multi-rótulo de 3 classes, 100, 001, 101, 111, etc serão considerados rótulos separados.
em geral, um espaço de classe da dimensão N, Não pode haver 2ᴺ nenhuma das combinações totais possíveis de etiquetas.
assim, não se decompõe em nenhum subproblema, mas prediz diretamente a combinação de etiquetas de classe como um todo.
vantagens & desvantagens de cada esquema
relevância binária é um esquema simples, fácil de implementar. Mas não considera o rótulo inter-dependência e, portanto, muitas vezes pode interpretar mal as relações de dados ocultos.
a cadeia classificadora lida perfeitamente com as relações de etiqueta de classe. Especialmente, nos casos em que algumas etiquetas de classe são sub-etiquetas de outras e a ocorrência de uma etiqueta de classe é fortemente dependente de outras etiquetas(relações pai-filho em etiquetas de classe. A etiqueta do filho pode ocorrer se a etiqueta do pai do iff estiver lá). Mas este esquema é complexo na natureza e sofre de um problema de alta dimensionalidade se o espaço de classe é grande.
o conjunto eléctrico de etiquetas funciona bem nos casos em que nenhuma combinação diferente de etiquetas de classe é menor. It is very a straightforward scheme as compared to the Binary Relevance & Classifier chain.
em todos os casos, é necessário um entendimento do conjunto de dados antes de se tomar uma decisão sobre um determinado regime.
métricas de precisão
em problemas de classificação multi-classe ou binários de rótulo único, a precisão absoluta é dada pela razão (não de instâncias de dados corretamente classificadas / total não de instâncias de dados).
Let’s see the scenario for the multi-label case using our example dataset. Se a pergunta com o id 241465 é classificada com etiquetas: ‘modelagem’,’ teorema-limite central’,’ graus-de-liberdade ‘ então o que podemos dizer? Etiquetas de classe reais no conjunto de dados eram ‘significância estatística’,’ modelagem’,’ teorema-limite central’,’ graus-de-liberdade ‘e’correlação espúria’. Nem é uma previsão completamente errada, nem é completamente correta. Se optarmos pela métrica de precisão tradicional correta contra a relação total baseada na precisão, definitivamente não seremos capazes de julgar o classificador. Precisamos de algo para avaliar a correcção parcial de um classificador multi-rótulo.
métrica de perda de Hamming
em vez de contar nenhuma instância de dados corretamente classificada, perda de Hamming calcula a perda gerada na cadeia de bits de etiquetas de classe durante a previsão. Ele faz a operação XOR entre a cadeia binária original de etiquetas de classe e etiquetas de classe previstas para uma instância de dados e calcula a média em todo o conjunto de dados. Sua expressão é dada por
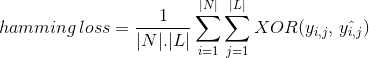
onde
|N| = número de instâncias de dados
|L| = cardinalidade da classe de espaço
yᵢ,ⱼ = real pouco de rótulo de classe j em instância de dados i
^yᵢ,ⱼ = previu pouco de rótulo de classe j em instância de dados i
‘de hamming perda de valor varia de 0 a 1. Como é uma métrica de perda, sua interpretação é inversa na natureza ao contrário da relação de Precisão normal. Menor valor da perda de hamming indica um melhor classificador.
precisão de subconjuntos
há algumas situações em que podemos ir para uma relação de precisão absoluta onde a medição da combinação exata de predições de rótulo é importante. Pode parecer relevante no caso do rótulo “power-set”. No cenário multi-rótulo, é conhecido como precisão de subconjunto.
aparte destes dois, a precisão de cada classificador binário individual pode ser avaliada por outras métricas tradicionais como a razão de precisão, pontuação F1, precisão, Recall, etc e curvas ROC.
isto é tudo sobre modelagem teórica para classificação multi-etiqueta. Veremos um estudo de caso usando dados reais no próximo artigo. O código de exploração de dados está disponível em Github.
recentemente fui autor de um livro sobre ML (https://twitter.com/bpbonline/status/1256146448346988546)